Hello,
I would like get text from image on webpage via OCR but the command OCRExtract always sends some error. My script can click in the image, the script can download the image to my computer but to get text from the image is not possible.
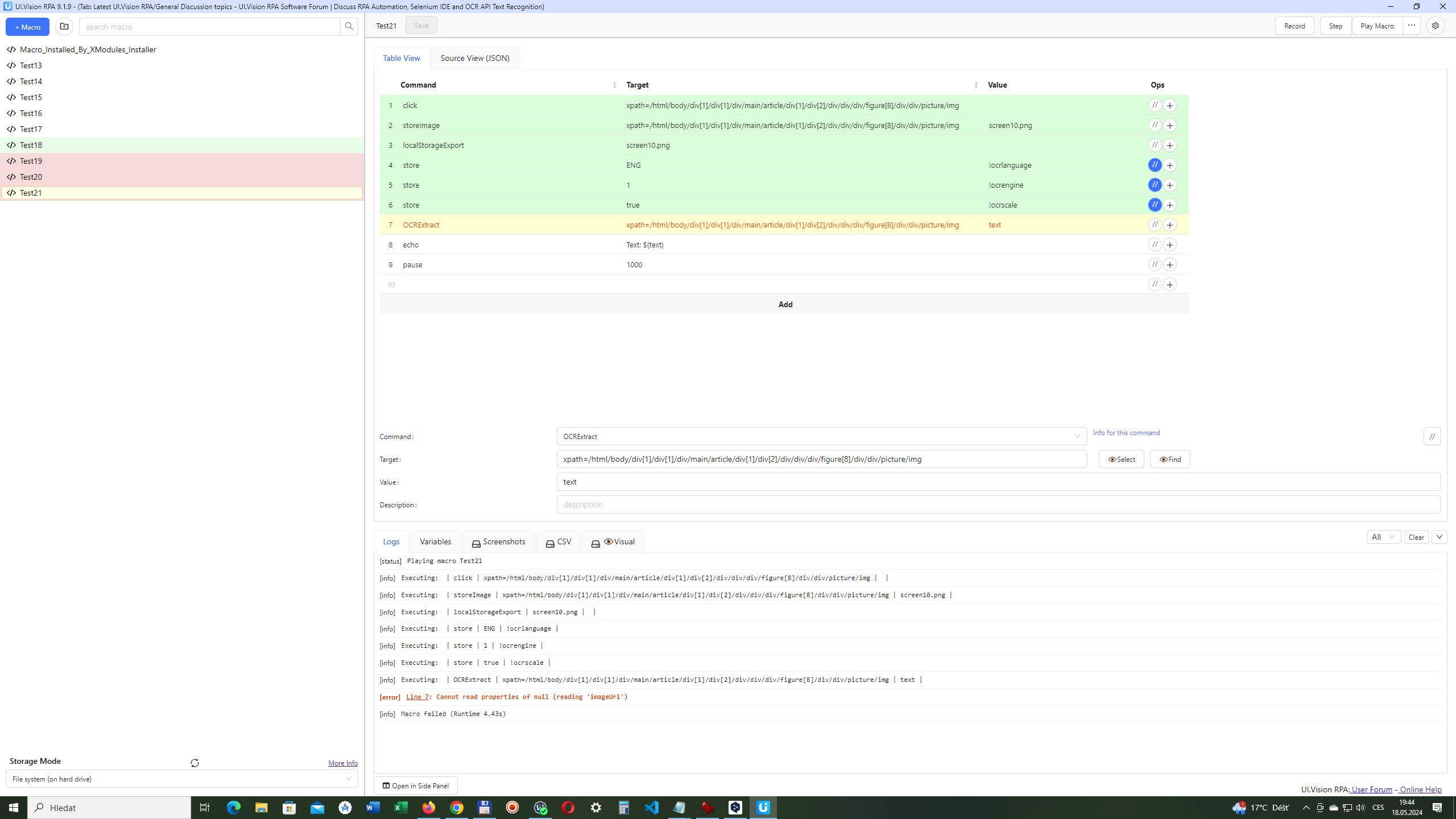
In the OCRExtract when I into Target write xpath=/html/body/div[1]/div[1]/div/main/article/div[1]/div[2]/div/div/div/figure[8]/div/div/picture/img, then macro sends “[error] Line 7: Cannot read properties of null (reading ‘imageUrl’)”. When I into Targer write screen10.png then macro sends "[error] Line 7: Error #120: visualAssert: No input image found for file name ‘screen10.png’(more info)"
Can you help me please?
Thank you very much.
Orna