Hi
Sometime i use the xpath with a text to detect some elements in the page
I use this command
XPath //*[text()[contains(.,‘General Web Automation’)]]
https://ui.vision/docs/selenium-ide/click#changingid
Now i want to know how i can choice an element if in the page there are multiple elements with the same text in this case “General Web Automation”.
If in a page there are 5 times the text “General Web Automation” and i need to detect the 3° third element how i can edit the xpath ?
Thanks
Not sure it’ll work, but try like this
XPath //*[text()[contains(.,‘General Web Automation’)]][3]
1 Like
I tried it but it seems not to work
I don’t know. Works for me. Have a look.
{
"Command": "open",
"Target": "https://rarlab.com/download.htm",
"Value": ""
},
{
"Command": "click",
"Target": "xpath=(//*[text()[contains(.,'RAR 5.71')]])[5]",
"Value": ""
}
Hi, today I retry your code and inform you about the result.
Thanks
Hello,
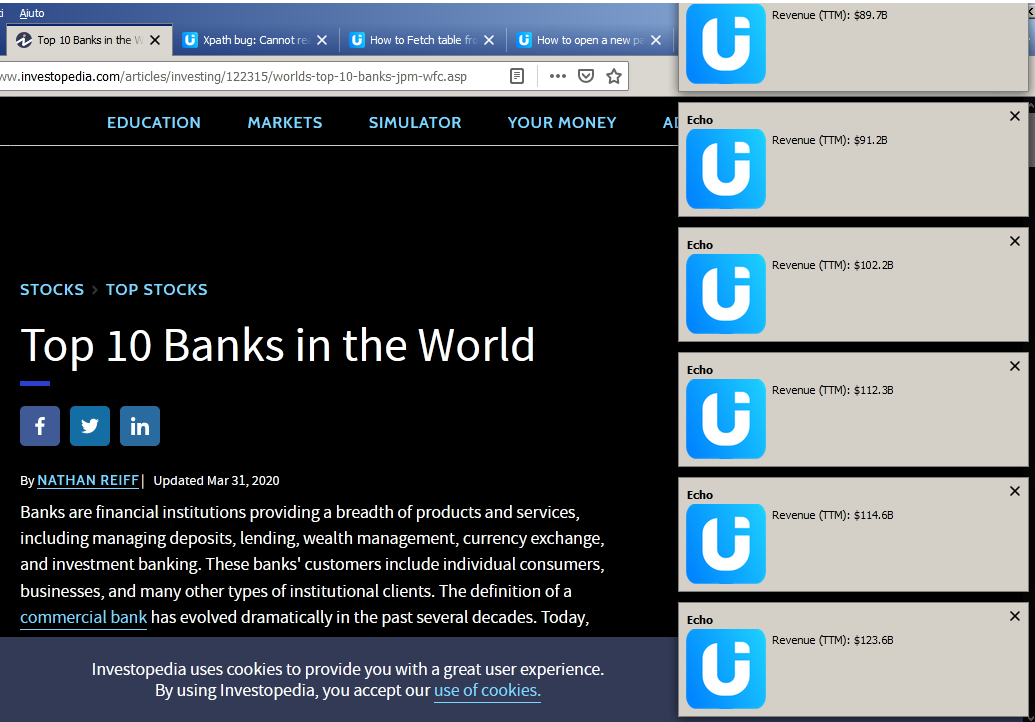
I’m having a similar problem. I’m trying to extract all the Revenue (TTM) lines from the list of Top 10 banks on this page:
If I run this code, I get the count of 10 which is correct because there are 10 banks listed and each bank has a Revenue (TTM)
{
"Command": "storeXpathCount",
"Target": "xpath=//*[@class=\"comp mntl-sc-block finance-sc-block-html mntl-sc-block-html\"]/li[1]",
"Value": "RTotal"
}
[echo] 10
But if I use this code to get the text for all matching Revenue (TTM) lines, I get only the first item! 
I want it to return all 10 Revenue lines on this page.
{
"Command": "storeText",
"Target": "xpath=//*[@class=\"comp mntl-sc-block finance-sc-block-html mntl-sc-block-html\"]/li[1][contains(.,'Revenue (TTM):')]",
"Value": "RMatches"
},
[echo] Revenue (TTM): $123.6B
Where am I going wrong?
thanks!
Hi
I solved for you the problem with a new macro code it store all revenue in the page, you can custom the number of value to store with the variable times (i setted it to 10).
You can save in csv of in variables the result after store.
Macro code
{
"Name": "Store_Multiple_Values",
"CreationDate": "2020-7-2",
"Commands": [
{
"Command": "store",
"Target": "true",
"Value": "!errorignore"
},
{
"Command": "bringBrowserToForeground",
"Target": "",
"Value": ""
},
{
"Command": "open",
"Target": "https://www.investopedia.com/articles/investing/122315/worlds-top-10-banks-jpm-wfc.asp",
"Value": ""
},
{
"Command": "waitForPageToLoad",
"Target": "10000",
"Value": ""
},
{
"Command": "times",
"Target": "10",
"Value": ""
},
{
"Command": "storeText",
"Target": "xpath=(//li[contains(.,'Revenue (TTM): $')])[${!Times}]",
"Value": "TTM"
},
{
"Command": "echo",
"Target": "${TTM}",
"Value": "#shownotification"
},
{
"Command": "end",
"Target": "",
"Value": ""
}
]
}
Image
1 Like
Thanks much @newuserkantu ! I will implement this. 
In the meantime, why doesn’t it work when I use //* , because //* means select all matching tags ?
//*li[contains(.,'Revenue (TTM):')]
I then decided to use a different approach.
I got the count as usual.
Then I used the full XPath in a While_v2 Loop and arrived at the same result.
/html/body/main/div[2]/article/div[2]/div[1]/ul[${i}]/li[1]
But I didn’t want to do it this way even though I solved the problem.
Thanks again for your help!
To close this out, looks like I read this wrong. //* means select all elements and not “all matching elements”.
thanks
You must add ( ) in xpath code and after you can add [1] (number of element)
//*li[contains(.,'Revenue (TTM):')]
Must be
xpath=(//*li[contains(.,‘Revenue (TTM):’)])
Look my macro code