Elster
1
Good evening dear community,
while exploring the sourceExtract command, I found out that using the * just reads the whole following left content from the html-code.
The pattern of the data I want to extract from html-code is the following one:
( 1 - 1 von 2)
Is there any solution to save just the value 1 in combination with csvSave?
My approach should be extendable. The number in bolt letters is in every case unknown. (Bigger numbers are possible).
My first attempt:
sourceExtract | *von | !csvLine
csvSave| testfile.csv
just saves more than I need.
Is there a regex solution possible? I don´t really understand how this syntax works.
Thank you in advance for your assistance!
Best regards
Fabian
Elster
3
Thank you for your first attempt to help!
I gave this regex formulation a try:
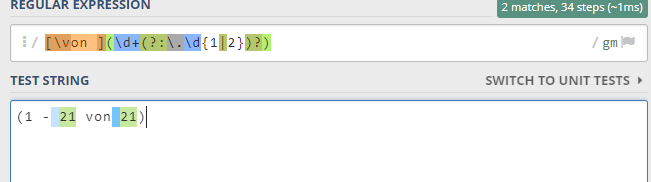
As I said before, I need to have a regex combined with sourceExtract-command.
I tried it with this attempt, to save the number in the middle.
sourceExtract | von* \d | !csvLine
I assume there is a better solution to this problem?
Elster
4
Is there a combination of xpath and regex possible?
ulrich
5
Why do you need a better solution? What is wrong with the regex version?
Elster
6
Hello ulrich,
I need the last two (green) numbers. The generated regex isn´t the solution.
Another attempt which was working in regex101 in a testsuite:
regex=(1 – (\d+) von.*)
But not in Kantu…why is that like this? Do I have to use other brackets?Does Kantu allow this syntax?
Thank you for your help!