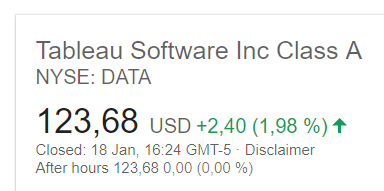
Image1 extracts 4 fields as expected. Image2 extracts only 3 fields - last cell (‘33’) missed. A bit strange. Images look similar - results are different. OCR online and my C# application give the same outcome. In apllication I applied scale=true&isTable=true&fileType=“JPG”.
What can be done to assure expected OCR behavior for both images?
Use a different OCR language. Especially Chinese or Korean give often good results for number OCR. (Note: I did a quick test and this is did not improve the OCR result in your case)
Increase the image area you send for OCR. This gives the OCR algorithms more context. I can not try this suggestion myself, as I don’t have the “larger picture”.
the image is small. You can pre-process it and increase the size by e. g. 200%. This is worked well in my test - all four numbers are recognized.
200% enalargement definiely improved processing. My sample works perfectly now. But more testing detected a lot of similar images where processing fails. Eg
.