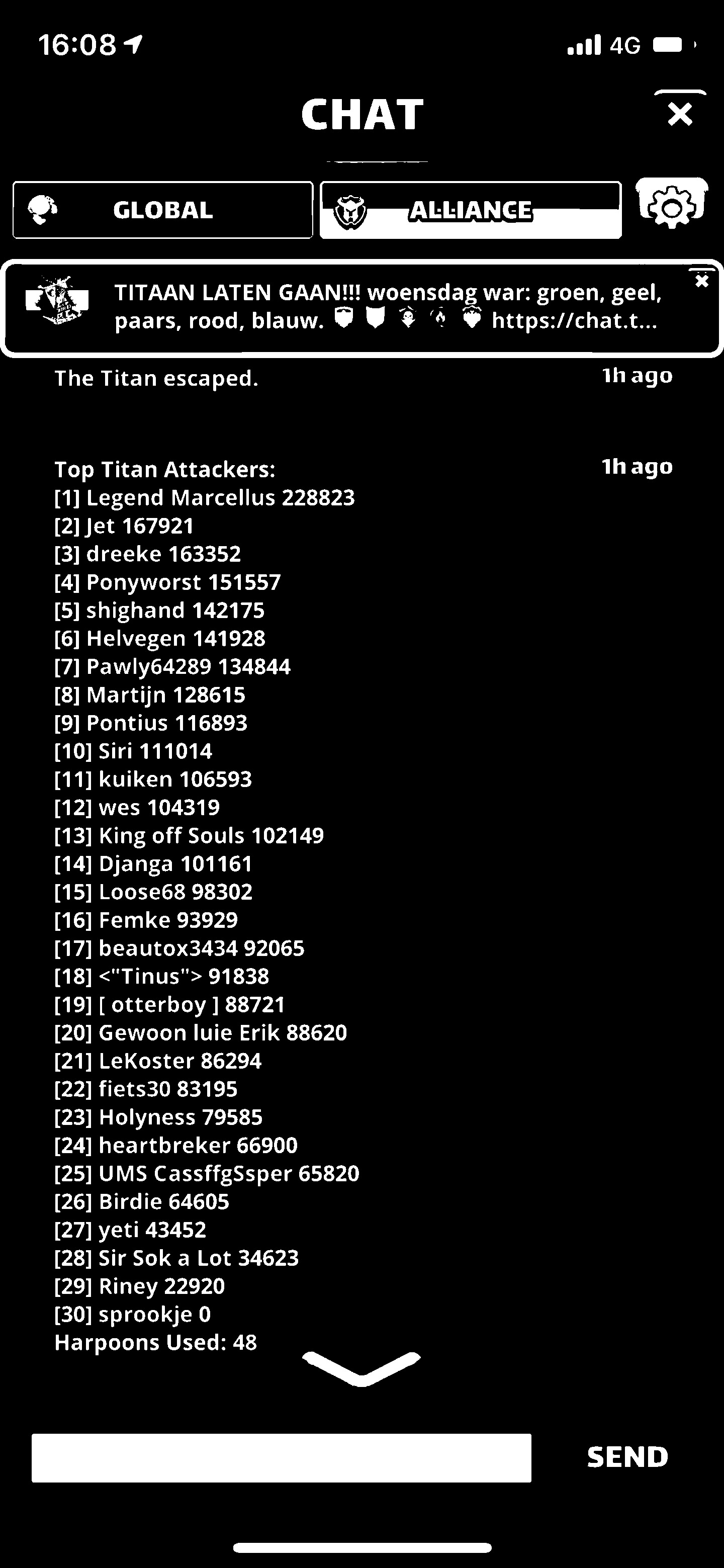
I have a picture with multiple names. One person has a name like this: <“Tinus”>
Whatever i do, it will always come back empty. As if these are html escaped. So the result will always be empty.
As a test i added lines of text and fed it to the OCR with <“thisismytext”> and it will also not parse it, it will come back as empty again. Why does it at least not come back with “thisismytext” ?
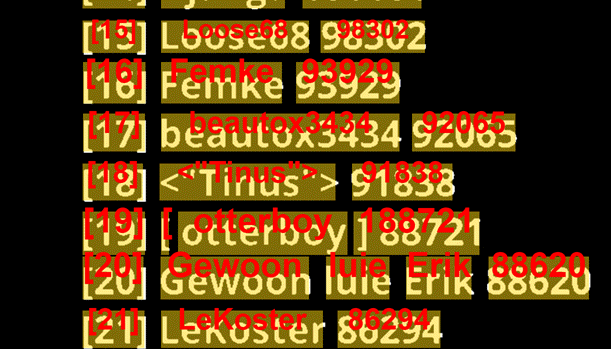
Presume you are using just the default settings. I was also using OCR engine 2. Have a friend that also used a similar setup and had issues with the ‘1111’ in a row. I’ll double check the settings and see if i missed something somewhere.
I did the same test as you did, it did do it better with OCRengine2. Turns out the ocrengine=2 was added in the wrong section in the call in my javascript…
The text does get a better match but the [ ] around the numbers do have more false returns then ocrengine. Pretty darn unlucky. Ocrengine1 does all [xx] numbers correct but some text not ok where as ocrengine 2 does do all text just fine but the numbers sometimes incorrect.
Gues i’ll have to make some regex around it somehow.