Hello!
Thank you very much for your hard work—it is highly appreciated.
I am using your product via the API and have the following question:
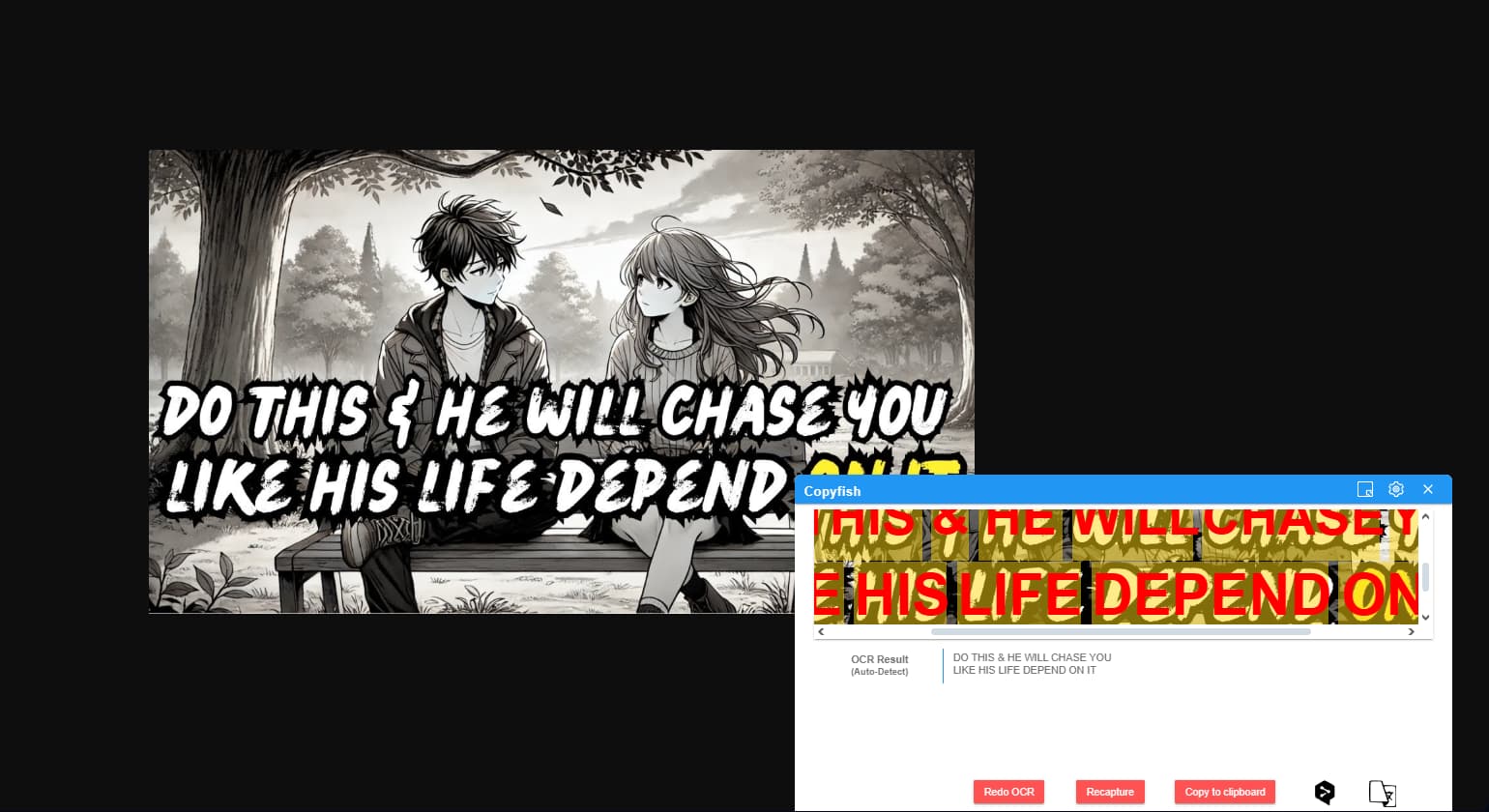
There is a type of image where text recognition works very well in the Opera/Chrome browser extension. However, recognition through the API is quite poor. Could you please let me know what I might be doing wrong?
In general, if the text is simple, it is recognized well, but more complex texts are recognized poorly, even though the browser extension handles them correctly.
I am attaching links to the images and code:
# --- OCR Function (Your Working Code) ---
def ocr_space_file(filename, overlay=False, api_key='11111111111111111', language='eng'):
""" OCR.space API request with a local file.
:param filename: Your file path & name.
:param overlay: Is OCR.space overlay required in your response.
Defaults to False.
:param api_key: OCR.space API key.
Defaults to 'helloworld'.
:param language: Language code to be used in OCR.
Defaults to 'eng'.
:return: Result in JSON format.
"""
payload = {
'isOverlayRequired': overlay,
'apikey': api_key,
'language': language,
}
try:
with open(filename, 'rb') as f:
r = requests.post(
'https://api.ocr.space/parse/image',
files={'file': f},
data=payload,
proxies=None # Disable proxies for OCR
)
# Check response status
if r.status_code != 200:
print(f"Error: Unable to connect to OCR.space API. Status code: {r.status_code}")
return None
# Parse JSON response
result = r.json()
return result
except requests.exceptions.RequestException as e:
print(f"Error while making a request to OCR.space API: {e}")
return None
except ValueError as e:
print(f"Error parsing JSON response: {e}")
print(r.text) # Output response for debugging
return None
# --- Function to Save Text to File ---
def save_text_to_file(text, file_path):
"""Saves text to a file."""
with open(file_path, 'w', encoding='utf-8') as f:
f.write(text)
What am I doing wrong? 
Hi,
Your screenshot is from Copyfish. This extension uses scale=true and ocrengine=2 as the default settings.
So two suggestions for your API call:
(1) Use scale = true
'scale': "true",
(2) And maybe also use OcrEngine 2:
'ocrengine': "2",
These parameters worked for me.
payload = {
'isOverlayRequired': overlay,
'apikey': api_key,
'language': language,
'scale': "true",
'ocrengine': "2"
}
Thanks it worked for me, now it recognizes more complex texts. Good luck to you.
1 Like
Hi! Could you please tell me if your API has stopped working? My OCR text recognition via API has not been working since yesterday.
Check the error code
PS C:\Users\abushaev> & "C:/Program Files/Python312/python.exe" i:/test4/test.py
Traceback (most recent call last):
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connection.py", line 198, in _new_conn
sock = connection.create_connection(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\urllib3\util\connection.py", line 60, in create_connection
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\socket.py", line 963, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
socket.gaierror: [Errno 11001] getaddrinfo failed
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connectionpool.py", line 787, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connectionpool.py", line 488, in _make_request
raise new_e
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connectionpool.py", line 464, in _make_request
self._validate_conn(conn)
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connectionpool.py", line 1093, in _validate_conn
conn.connect()
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connection.py", line 704, in connect
self.sock = sock = self._new_conn()
^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connection.py", line 205, in _new_conn
raise NameResolutionError(self.host, self, e) from e
urllib3.exceptions.NameResolutionError: <urllib3.connection.HTTPSConnection object at 0x000001F2BD910980>: Failed to resolve 'api.ocr.space' ([Errno 11001] getaddrinfo failed)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\Python312\Lib\site-packages\requests\adapters.py", line 667, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\urllib3\connectionpool.py", line 841, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\urllib3\util\retry.py", line 519, in increment
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.ocr.space', port=443): Max retries exceeded with url: /parse/image (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x000001F2BD910980>: Failed to resolve 'api.ocr.space' ([Errno 11001] getaddrinfo failed)"))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "i:\test4\test.py", line 44, in <module>
result = ocr_space_file(filename=image_path, language='eng') # You can change 'eng' to other languages
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "i:\test4\test.py", line 24, in ocr_space_file
r = requests.post('https://api.ocr.space/parse/image',
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\requests\api.py", line 115, in post
return request("post", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\requests\api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\requests\sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\requests\sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\Python312\Lib\site-packages\requests\adapters.py", line 700, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='api.ocr.space', port=443): Max retries exceeded with url: /parse/image (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x000001F2BD910980>: Failed to resolve 'api.ocr.space' ([Errno 11001] getaddrinfo failed)"))
PS C:\Users\abushaev>
The free OCR API was overloaded this morning. Sorry about that. The issue has been fixed now.
The PRO/PRO PDF endpoints were not affected, as they run on different servers.
1 Like
Everything is working now. Thank you! Where can I learn more about the paid version? I only use text recognition from images, exactly five images per day. I just need it to work smoothly without any overloads.
{kind=link}