Hello, here is my second question for today. I want to grab the multiple lines of text from page and save it into an csv file. However, the value I got seems to be empty. I’m pretty sure the xpath is correct because I just copied it from the inspector.
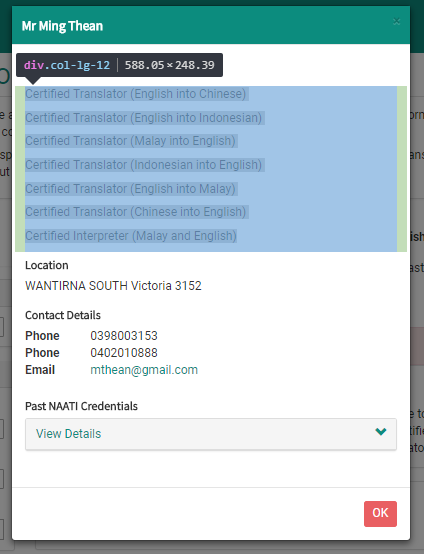
The texts highlighted in blue is what I want to grab.
Here is the xpath I copied from the inspector:
//*[@id=“contactDetailsModal”]/div/div/div[2]/div[2]/div
Thanks for that. I think storeText is the right command for me but I still can’t manage to get all the text I want with it. Here’s the URL and I’d appreciate it if you can have a look at it for me: Home Page .
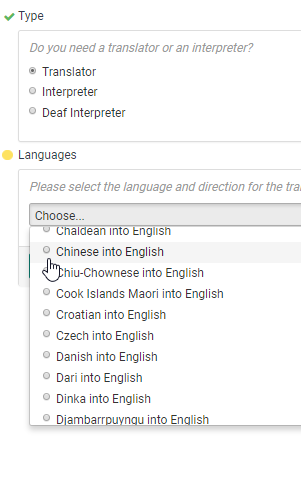
Choose Chinese into English at the language selection
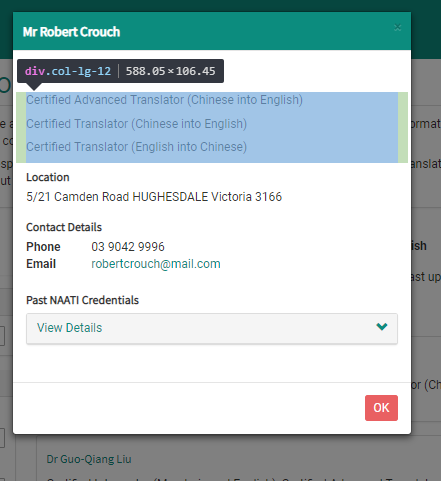
On the new page, click one of the results and a pop-up window will appear
I’d like to get all the texts highlighted in blue but can only get the first line using the xpath //*[@id=“contactDetailsModal”]/div/div/div[2]/div[2]/div . It works fine in another xpath based extension.
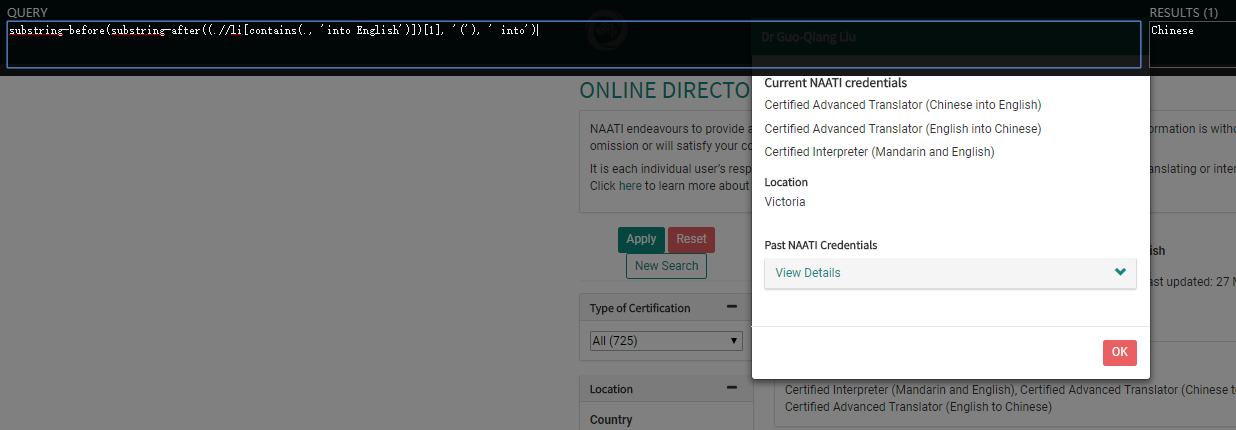
I’d also like to get the language other than English that the translator works with and I use the xpath substring-before(substring-after((.//li[contains(., ‘into English’)])[1], ‘(’), ’ into’) . That doesn’t work as well while it works in the other xpath based extension.
Hi Ulrich,
Thanks for the reply. I installed the beta version and it actually helped. Now I can get all the texts from a particular xpath. However, the beta version still can’t seem to recognise substring-before(substring-after((.//li[contains(., ‘into English’)])[1], ‘(’), ’ into’) . The other extension I mentioned is Data Miner and it has no problem locating that element for me. I also tested the xpath with Xpath Helper and it works too. Do you know what I should do to make it work? Or is it a bug that needs to be fixed too?
The syntax is:
storeText | xpath=substring-before(substring-after((.//li[contains(., ‘into English’)])[1], ‘(’), ’ into’) | data
store | ${data} | !csvline