I have been using the OCR.space API for a long time and it has been great, but recently I started using the table recognition feature for the first time, and I noticed that it is not as good as it could be. I have a one major issue with it. That is how there is no way to see where the columns are divided. Especially on the the JSON “lines”. This issue is more important in tables that have spaces, such as names.
It would be ideal if there was an independent table object with columns and arrays, but alternatively, a CSV format or even just a character (like a | ) to just signify that a different column is beginning, would significantly increase the functionality of the table recognition feature.
I wonder how hard of a update that would be and if I can expect it in the future.
We fully agree that table detection and extractionwith separators between the columns would be great to have, and we are looking into adding this feature “next year”
=> How do your tables look like? Do they have borders or are they borderless (non-gridded)? If you can upload a few images that would be helpful.
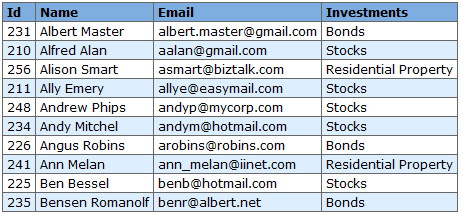
I don’t have a strictly set use case for it, but this was one of the sample tables that I was using.
Most of the ones I plan on doing have distinguishable grids.
Nice to hear that column separation is coming in the near future. As a developer myself, I understand that strict timeframes may be hard to give, but could you elaborate as to when next year I can expect it?
Anyways, thanks for your response and happy holidays!