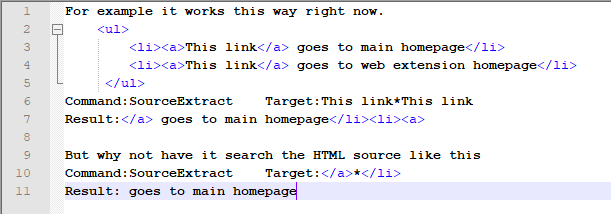
I have been looking at the command SourceExtract https://ui.vision/rpa/docs/selenium-ide/sourceextract-sourcesearch
From the documentation and testing is basically looks for the source string between two plain text strings. What I do not get is why not look for the string between the actual source instead of searching for plan text.
Or is this possible and I missed something?
Note I used a picture of the code because the Post editor said I was posting with too many links…
Yes, I solved it. But it’s not what I thought of at the first moment, but it works.
You need a executeScript_Sandbox command. In that command, you put in some Javascript command to chop off the others, so you can get the link at the end. You can learn how to use executeScript_Sandbox in here.
For example, in my example, I should use some substring or slice command to chop off the <html and </html> part. It depends on what sourceExtract pulls out, and then you decide what Javascript command to put in.