The screenshots are useful. They helped us to identify the OCR issue: The pink area is too small. In general, a bit more area and some words as context help with number OCR accuracy.
Test: I tried with two different pink boxes:
(1) Number plus some text (recommended) => works fine even with single digit numbers! After OCR, you can then remove the text that you do not need with string split.
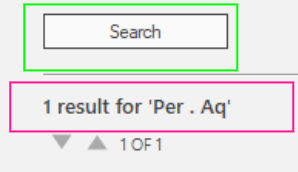
(2) Just number => This avoids the need for string split, but makes the OCR less reliable, especially for single digit numbers. The OCR might think that this lonely number is not a character and ignores it.
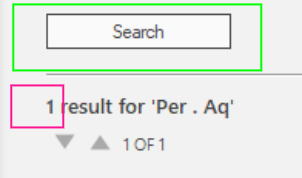
Here is a screencast of my test. To test, I drop your images into a browser and then run desktop automation on it:
Hint: At 1:05 in the video I switch to the Screenshot tab to show that you can always use “_lastscreenshot.png” to verify what image gets actually sent to the OCR engine. And if needed you can then export this image and test the OCR directly with the online ocr page - that can be useful for debugging OCR issues.
See also: OCRExtractRelative: A larger pink box OCR area is usually better