Is there a way to remove spaces in OCR extracted text? Whenever I use that and paste it the result has spaces at the beginning and the end.
DemoPDFTest_with_OCR has some examples for this.
In this macro you find this regular expression. It removes spaces and line breaks. Use it with ExecuteScript_Sandbox:
return ${q}.replace(/( |\n|\r)/gm, "")
Complete string replace test macro:
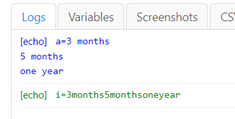
{
"Name": "replace2",
"CreationDate": "2023-5-11",
"Commands": [
{
"Command": "store",
"Target": "3 months \\n5 months \\none year",
"Value": "a",
"Description": ""
},
{
"Command": "echo",
"Target": "a=${a}",
"Value": "blue",
"Description": ""
},
{
"Command": "executeScript_Sandbox",
"Target": "return ${a}.replace(/( |\\n|\\r)/gm, \"\")",
"Value": "i",
"Description": "replace space and cr"
},
{
"Command": "echo",
"Target": "i=${i}",
"Value": "green",
"Description": ""
}
]
}
![]() See also: string handling
See also: string handling