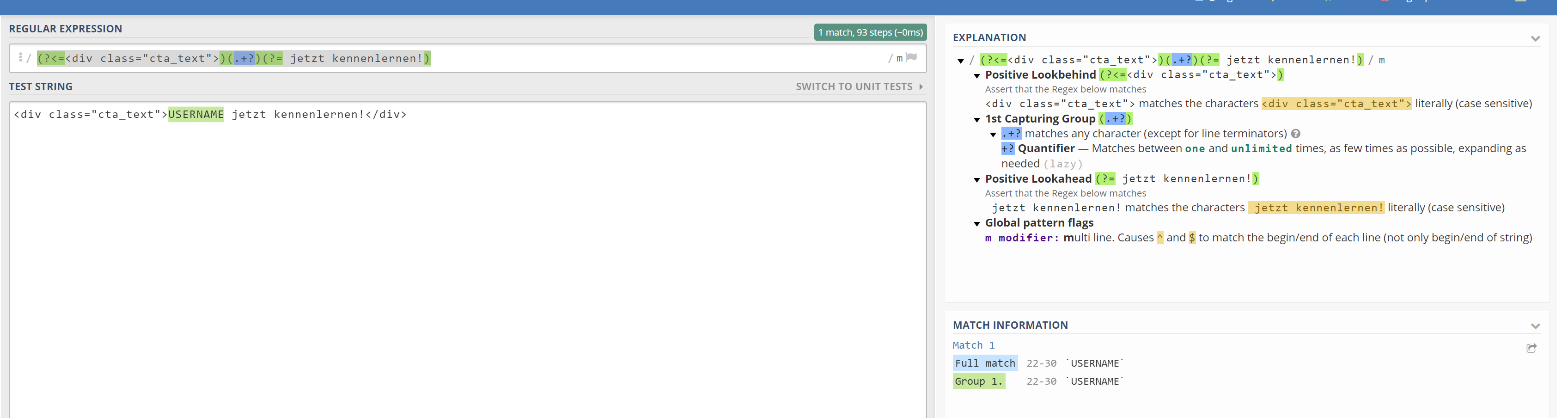
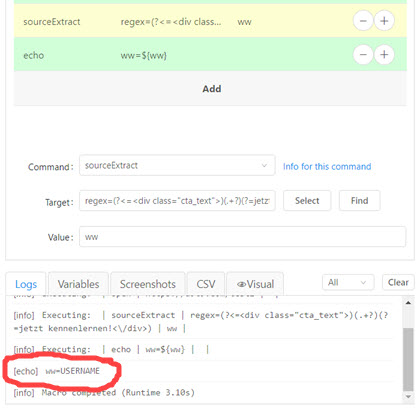
PS: My point is that this is not an issue with Kantu’s SourceExtract command, but a general regex question. I hope someone better at regex than me can answer it
I tried it again with regex101.com but it just claimed the / inside the regex as “unescaped delimiter (which) must be escaped with a backslash ()”.
It’s not important, so I deleted it. Works on regex101.com, but not on Kantu.