I am trying a file which contain English & Arabic text using Engine =1&lang= ara Params.
Extract text are not accurate specially for date.
Please suggest
I am trying a file which contain English & Arabic text using Engine =1&lang= ara Params.
Extract text are not accurate specially for date.
Please suggest
Hi, can you please post a test image?
Thanks for the test images. I am from the OCR team. Did you try with our OCR Engine3? It supports Arabic OCR as well.
=> Is the Engine3 Arabic OCR result better (or worse)?
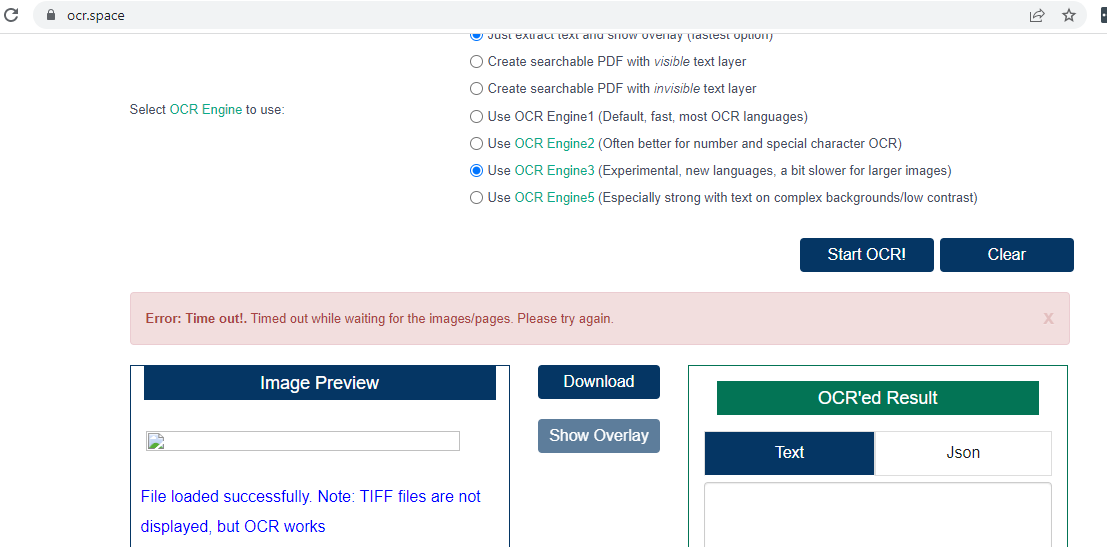
We are getting “extract-Timed out waiting for results” this error when trying OCREngine =3 params.
Passing base64Image data.
Filesize: 4.6MB
Also tried direct from https://ocr.space/.
Please suggest.
Also Is it possible when we pass language = Arabic, English text come left to right. Currently document in mix language Arabic-English and when passing Arabic language English text coming right to left which is incorrect for English.
Engine3 is still under development. Combined English/Arabic support is planned for one of the next updates.
But for the Arabic result, is it better than Engine1?
Yes-Engine3 better for Arabic.
Is it possible when we pass language = Arabic, English text come left to right ?