I’m struggling to understand what is meant by the following;
“file : Multipart encoded image file with filename”
I am trying to post a PDF file but I am returned a 411 - “Content-Length” required error. I am unsure what is meant by a encoded image file, I am just trying to POST a PDF file. Also, I am unsure what is meant by “with” filename. Should I be sending the PDF document in the body of the HTTP POST request or is it a value in the “file” header request.
Please advise and all your help is much appreciated.
Thanks for the swift response ulrich, this worked in postman, however, I wonder is postman is in fact encoding the document before posting it? Would you know?
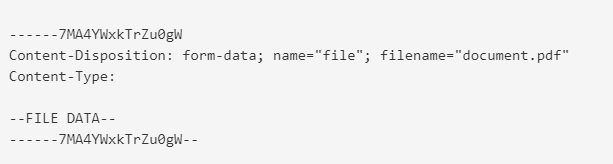
Hi ulrich, thank you so much for your help. This did in fact work somewhat, though not completely. I had to build the entire body for the POST request (it’s basically just a raw string which looks like this;
This is my result;
{“ParsedResults”:[{“TextOrientation”:“0”,“FileParseExitCode”:1,“ParsedText”:"",“ErrorMessage”:"",“ErrorDetails”:""}],“OCRExitCode”:1,“IsErroredOnProcessing”:false,“ProcessingTimeInMilliseconds”:“437”,“SearchablePDFURL”:“Searchable PDF not generated as it was not requested.”}
I’m wondering whether or not the API expects a JSON formatted object (containing the PDF) in the actual body of the POST request.
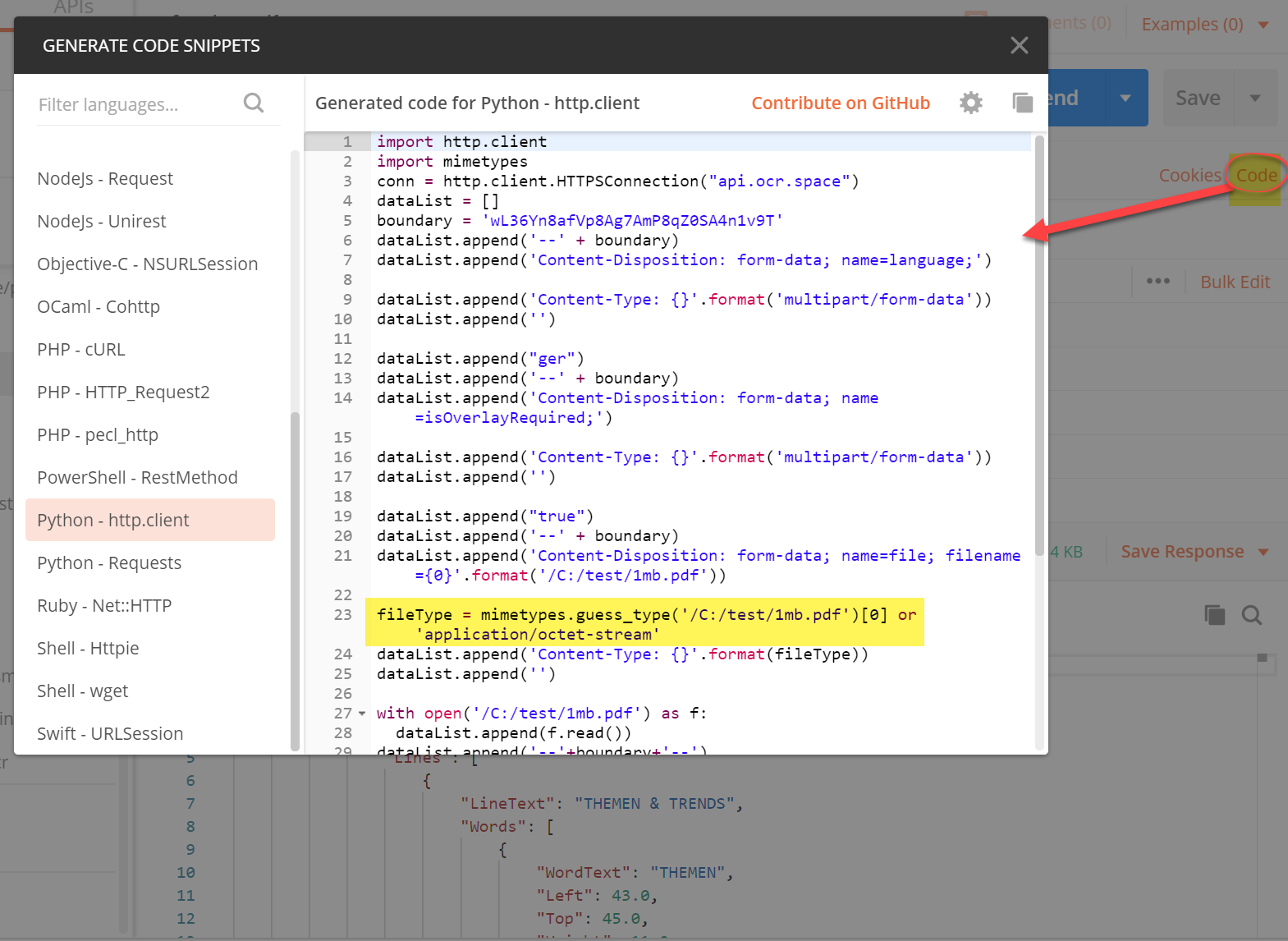
Ok so I’ve tried a few different things. I think everything is generally ok, however, when I POST a base64 encoded PDF, I get a response of “PDF Corrupted”.When I sent the raw PDF contents, the ParsedText in the JSON is empty. I think I would need someone on the OCR.Space side to check what they’re receiving, may be something is being lost during the HTTP communication, but I can’t see that from my side.
Ok so I found the solution, it is actually very simple and many people have experienced a similar issue to no avail, and I can see why; it would help if the OCR api docs were updated to make it clearer because what stumped me was that a different method for posting PDF document has been documented, but in fact it’s exactly the same as posting a regular base64 image. Any way, so the solution is as follows;
Instead of trying to upload an actual file (or blob, which is the file content), POST a “Data URI” instead. Note: it’s not a URL as you’ll see below;
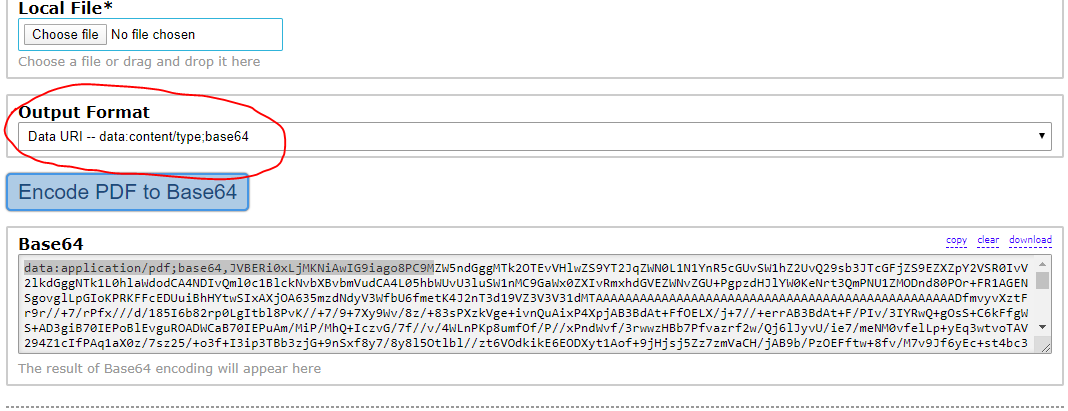
Convert the file into base64 string.
Append the following to the front of the base64 string;
NOTE: Upload the file and select the correct output format - Data URI.
Add this to the form body with a key, in this case it would be “base64image”, note this isn’t literally an image as in a .gif, .png or .jpg, it actually means the base64string. See screenshot below;


{kind=link}