Hey fellow OCRers,
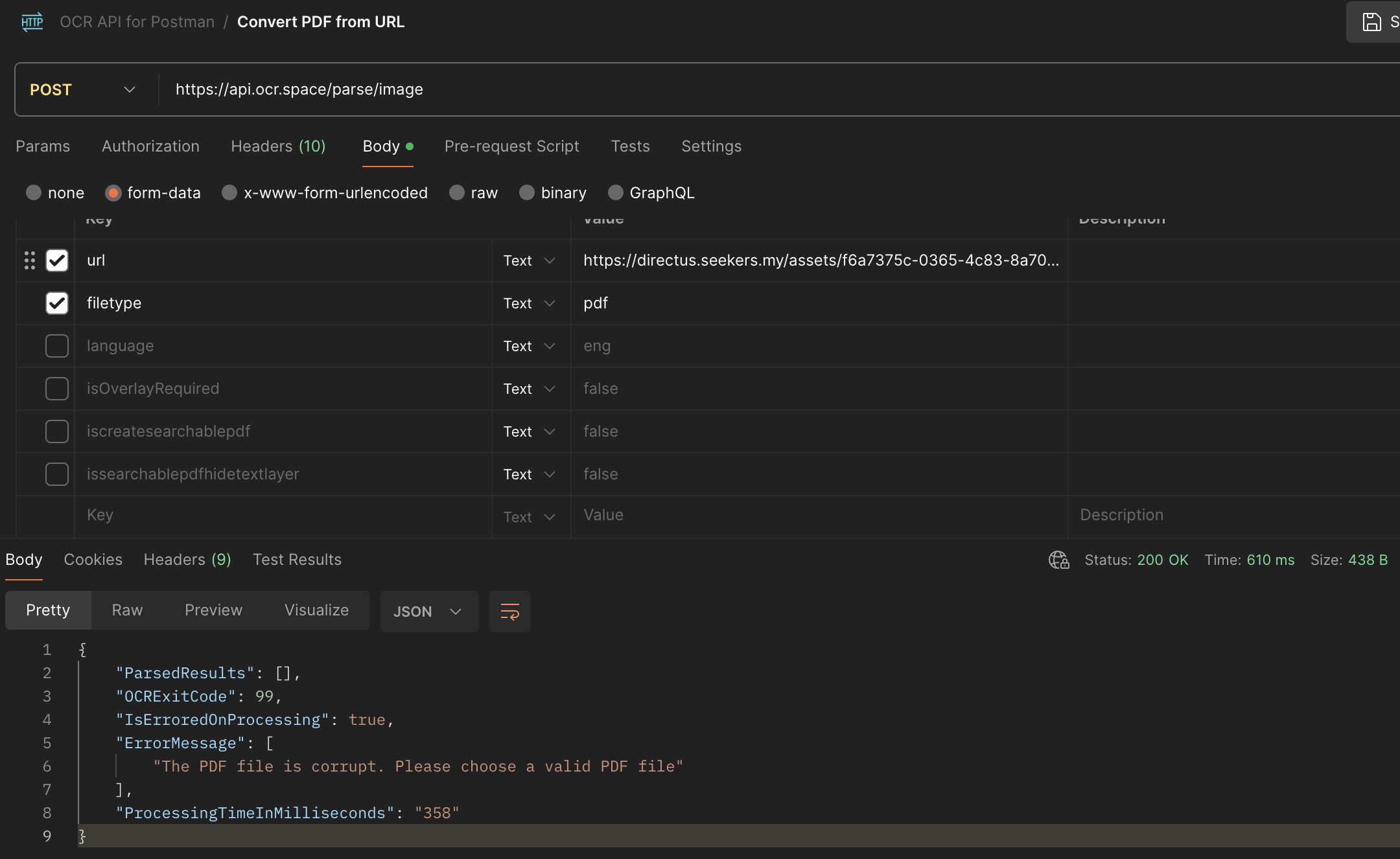
There seems to be an interesting issue when trying to OCR pdf files resulting in
“The file or its content is corrupt. Please choose a valid file for parsing.” errors.
To replicate:
- Use the given OCR Space postman ‘Convert PDF from URL’ collection.
- Change the endpoint to the free api ‘https://api.ocr.space/parse/image’
- Use this value as “url” :
https://directus.seekers.my/assets/f6a7375c-0365-4c83-8a70-4e1d95ebeea7?access_token=V8U3xiPIME3GRno_LJuc6t-IHXwRn4wl
Accessing the url directly in a browser does show the PDF file, but the POST api call will return with the error above instead.
Wonder if anyone else have had a similar issue.
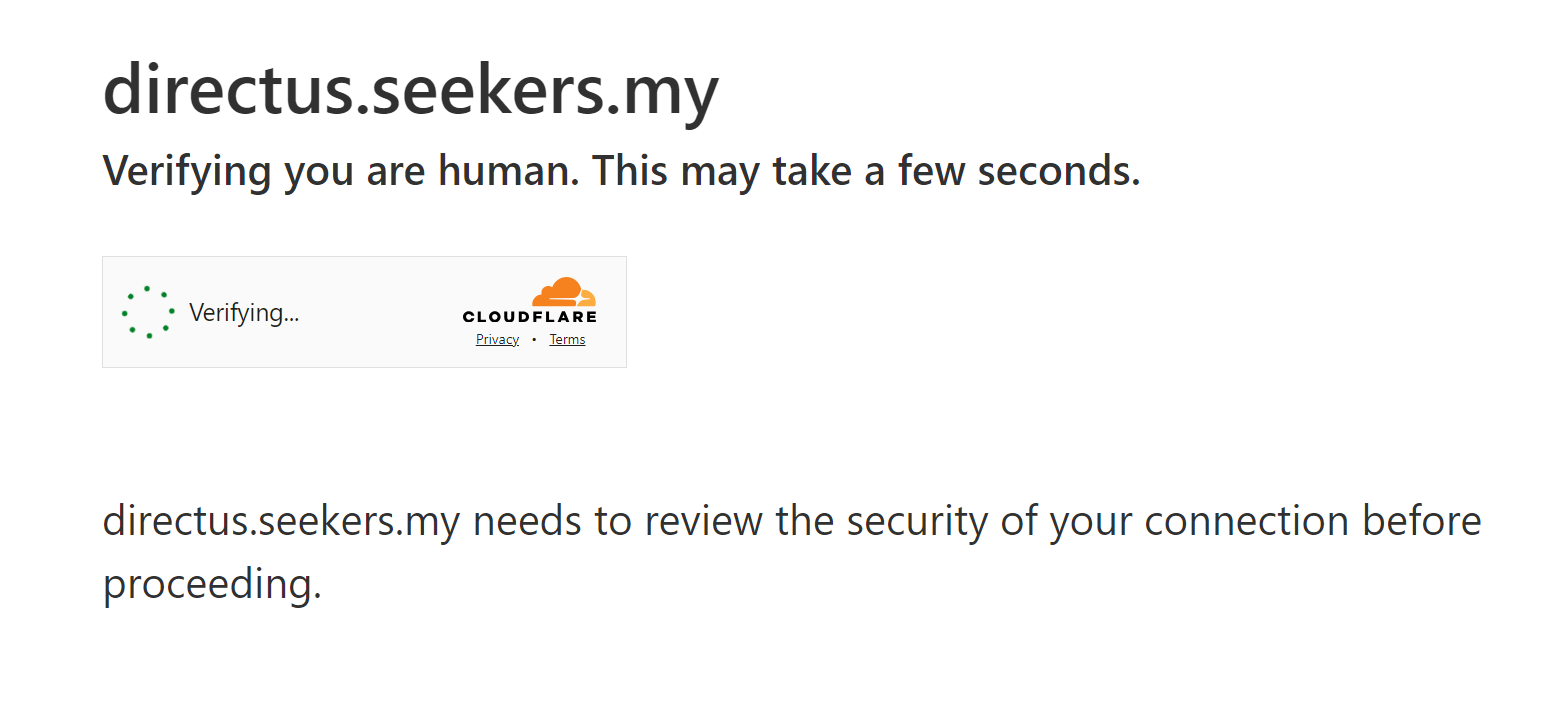
I clicked on your PDF link and got a Cloudflare captcha. I think that is the issue. In other words, the api can not download the document:
One option could be to white-list the OCR API endpoint IP address, so that no captcha is shown?
1 Like
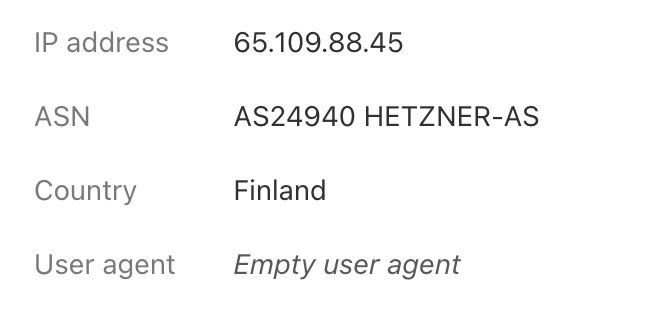
Hats off to you sir. The IP ended up being different from the API endpoint IP. Hope it might help anyone facing same issue.
This for the https://apipro1.ocr.space/parse/image endpoint:
1 Like
@rafazafar Thank you for pointing this out. It is just as you discovered. We have many PRO ocr processing servers, and the IP address of the PRO endpoint is usually not the OCR server that actually downloads the file for processing.
Having said that, you (and any other PRO user) can always contact our OCR API tech support for a recent list of all PRO1 and PRO2 IP addresses.
All PRO servers are inside the EU, so the IP address will always be a European one. Maybe that information helps already.