But it always results in an empty output no matter what.
I also played around the variables !OCRScale and isTable activated, or !OCREngine set to 2, but still no luck
Here is the __lastscreenshot.png :
Any recommendation ?
Thanks a lot in advance
Now that I think about it, is __lastscreenshot.png the area that OCRExtractRelative captures ?
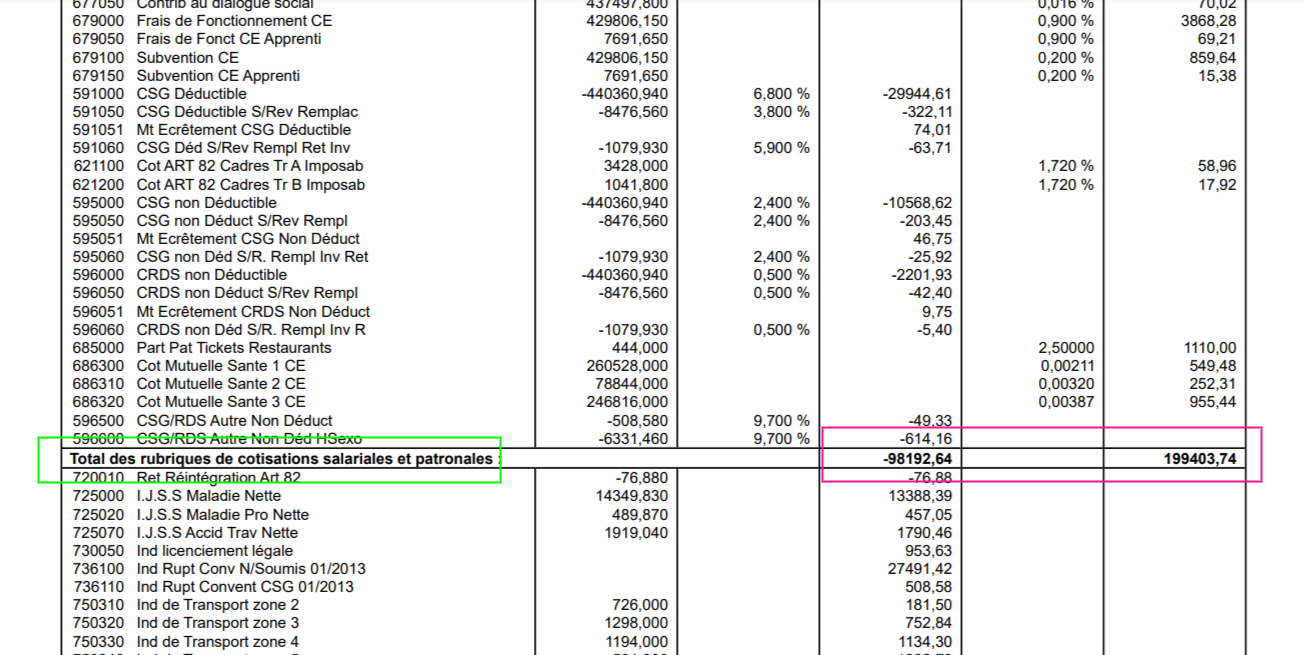
Well it very much seems like it’s the wrong lower part portion of the page.
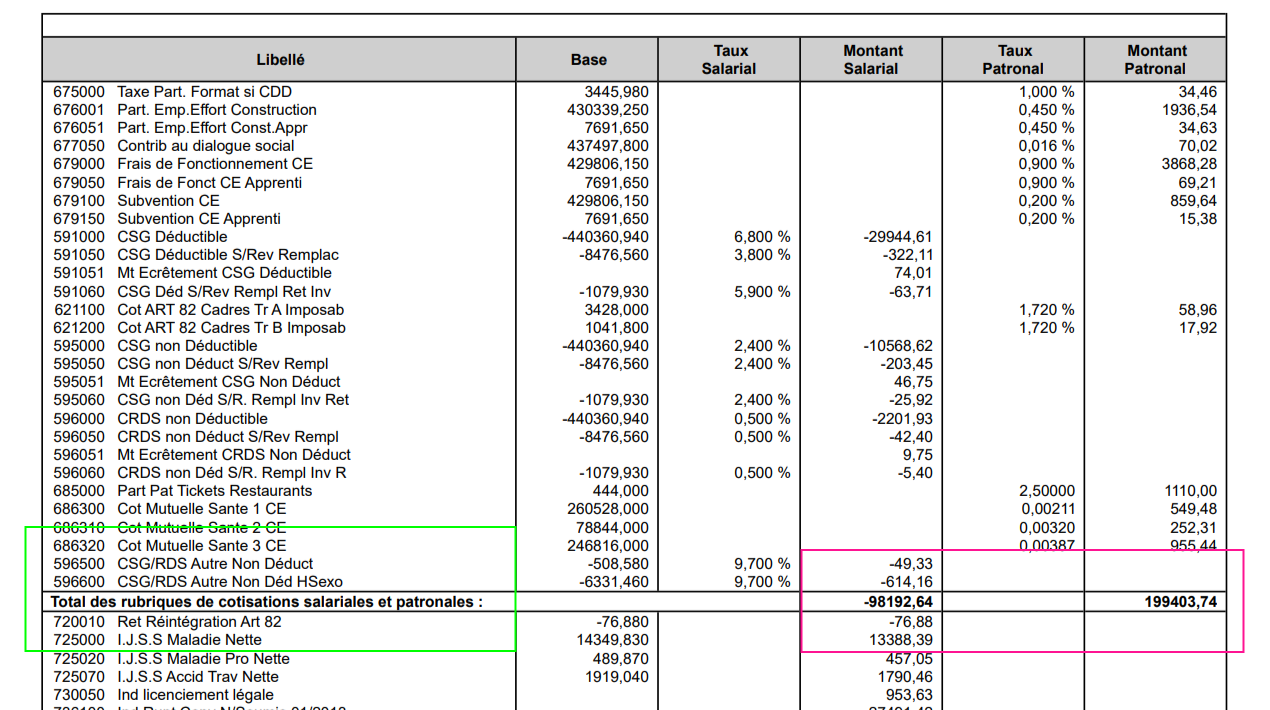
So the green box would be the culprit ?
It could be helpful to add that my PDF is actually full text, so if I understand this right :
I might not need OCR commands, as my PDF is already searchable.
That being said I have no clue how to make a search inside my PDF.
Something like storeText with an xpath say, “xpath=(//*[text()[contains(.,'My Keyword… ')]])” ?
I’ll try that
EDIT : doesn’t seem to work but I forgot to mention that I’m using an embedded Acrobat Reader inside an iframe :
In this case I would recommend you use XTYPE and simulate the “copy & paste” commands with CTRL+A (select all text in PDF) and then CTRL+C. Then, inside the macro, the data is in the !clipboard variable.
You can also try to use a triple-click to just select the line you need:
XCLICK | | #tripleclick
XType | ${!KEY_CTRL+KEY_C}
As mentioned below, you might need to switch to desktop automation, if the coordinates are wrong in the web automation mode.
PS: storeText works only on websites, not PDF.
PPS: This answer is a solution without OCR. The next answer is an idea to fix the OCR capture. This way you have 2 suggestions to try
Now that I think about it, is __lastscreenshot.png the area that OCRExtractRelative captures ?
Yes!
…(then) I’m pretty sure the spot it tries to capture is way below the target (pink box)
I agree. I assume the iframe and the embedded PDF confuse the BROWSER coordinates calculation of UI Vision.
=> For OCR to find the correct area, switch to desktop automation mode, then it will work! You can either switch in the UI Vision IDE or use this macro command: XDesktopAutomation | true
In this case I would recommend you use XTYPE and simulate the “copy & paste” commands with CTRL+A (select all text in PDF) and then CTRL+C. Then, inside the macro, the data is in the !clipboard variable.
Thanks, that did the trick !
Now I’m on my way to parse the !clipboard content