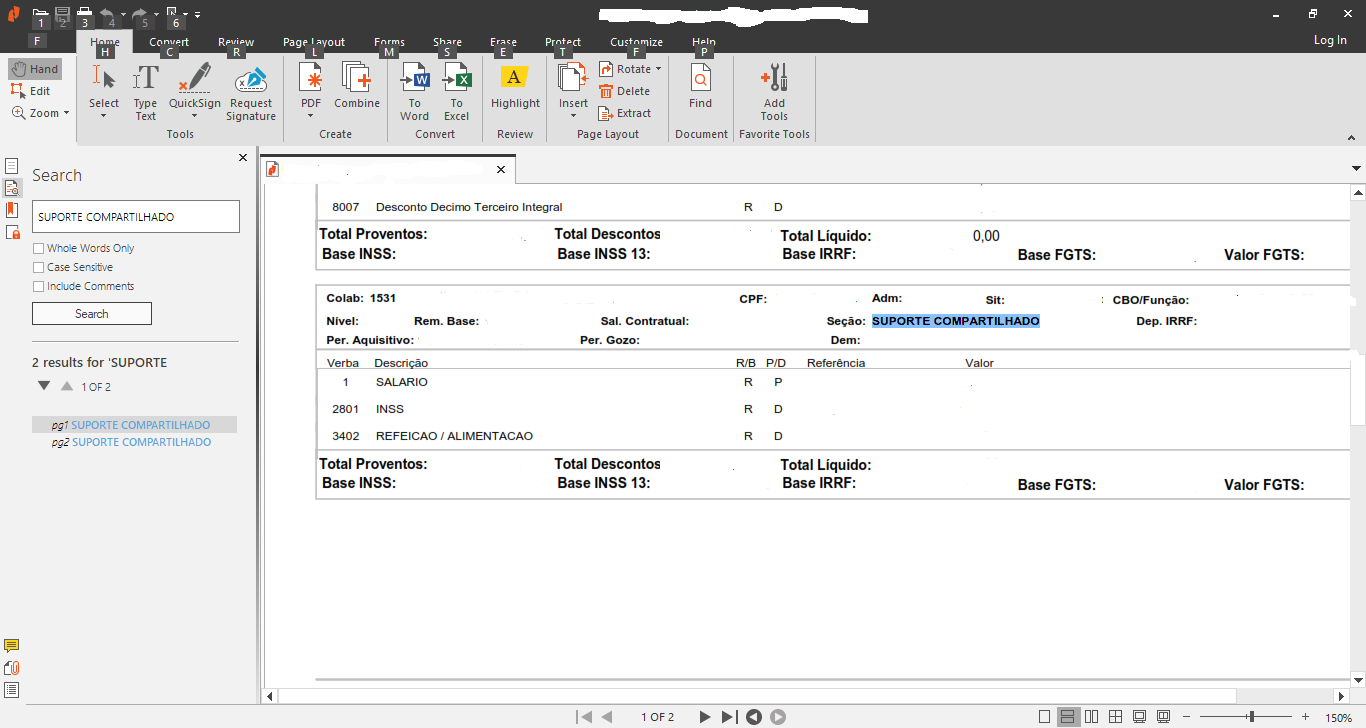
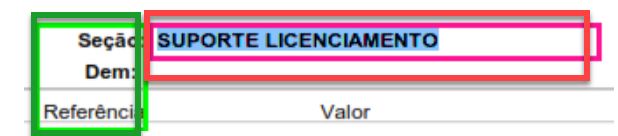
I am facing a problem with OCRExtractRelative that truncates a name. It works fine most of the times but for two specific cases, same names that are read correctly a dozen times, are truncated. The green box has already been increased and the pink box is large enough to capture, once the words are captured correctly for all other cases.
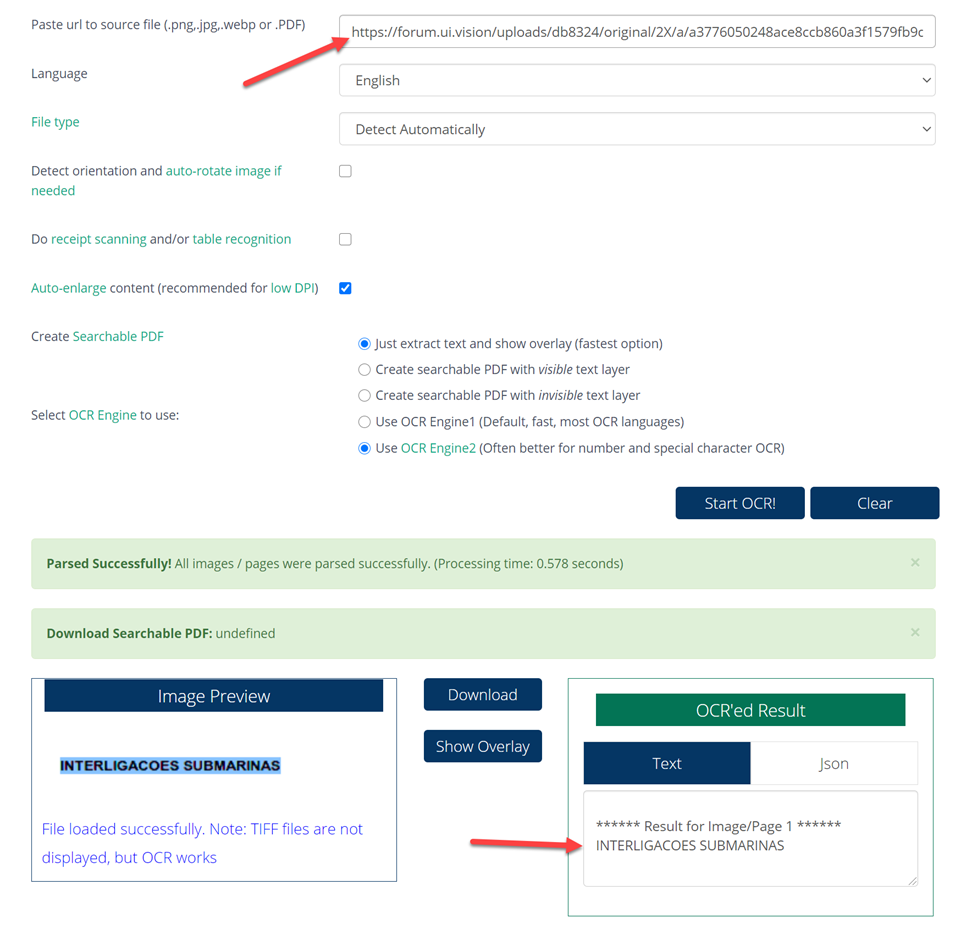
Last screenhots show that the images are fully captured. Variable contents, however, are truncated: SUPORTE COMPARTILHADO shows as SUPORTE COMPARTILHAD and INTERLIGACOES SUBMARINAS shows as INTERLIGACOES SUBMARI.
Please find attached a sreenshot of the page, relative image utilized and the last screenshots of the two cases.
I found that with a little bit more white space around the text the OCR API is usually better. Try with a bigger pink box. For that, you can also shift the green box a bit more to the left. Maybe like this:
Are you already using OCR Engine2? It is better for Western text OCR.
Hi Ulrich,
Yes, I am using OCR 2. I tried some options with more space around the text (before, above and below), but, unfortunately, the two specific cases still return truncated information.
Anyway, thank you again for sharing your knowledge.
Best regards
HI admin,
The two _lastscreenshot.png for these cases are the last two files attached above. They seem fine, the correct infomation is there and are: SUPORTE COMPARTILHADO and INTERLIGACOES SUBMARINAS. For some reason, the variable that contais the information is truncated.
Thanks for your attention.