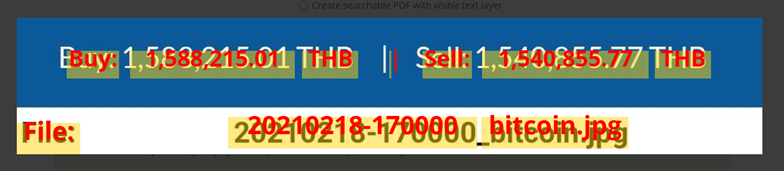
Hi,
I’m using the OCR.SPACE extension for MIT App Inventor to grab some numbers from a website…
I attach a working and a non-working version to this report.
The non-working version simply drops the numbers… and this always happens if the number looks like 1,xxx,xxx
Any idea what to do?
Thx for your help and this absolute fantastic service.
rgds, Man