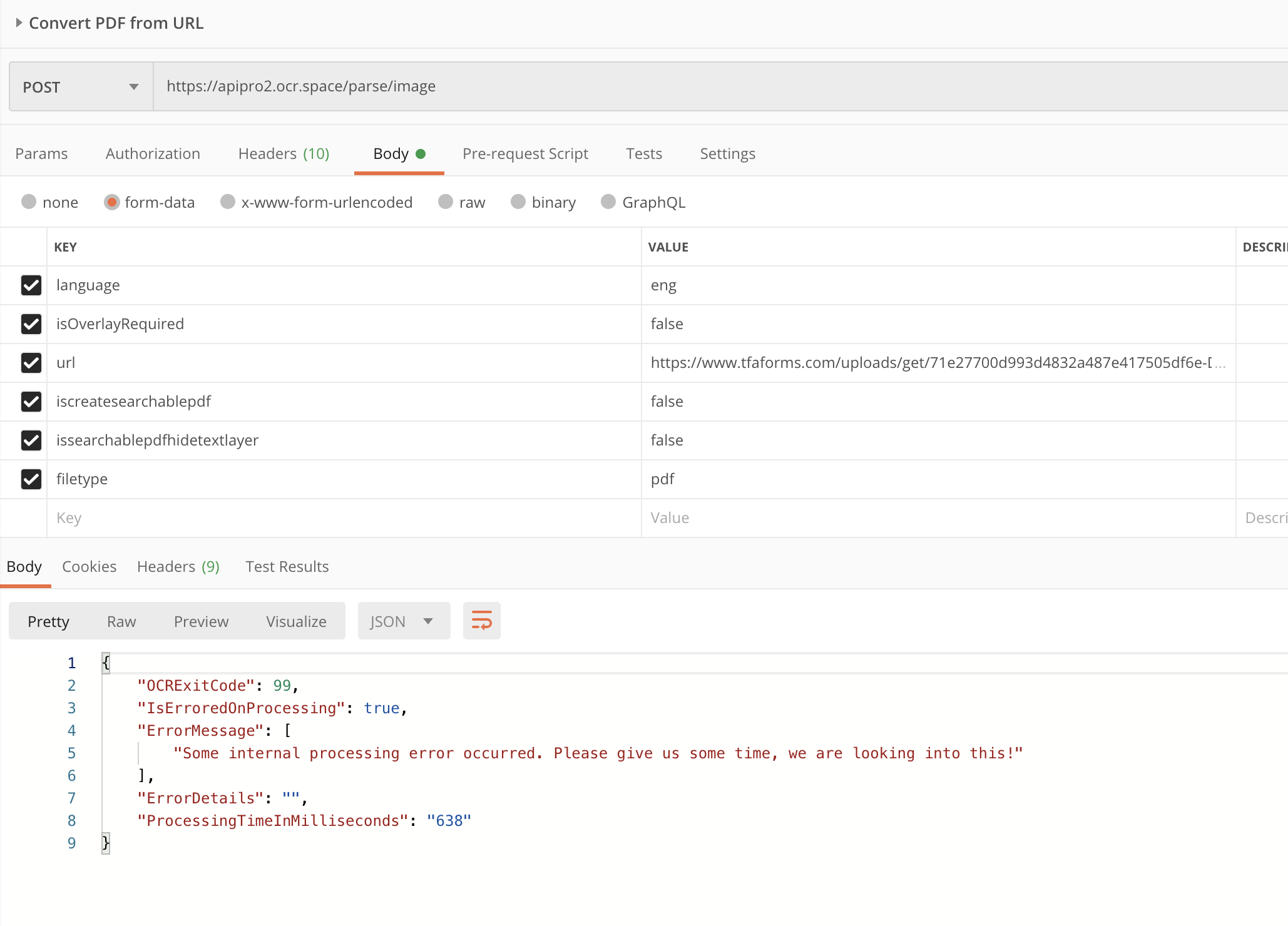
{#1292 ▼
+“OCRExitCode”: 99
+“IsErroredOnProcessing”: true
+“ErrorMessage”: array:1 [▼
0 => “Some internal processing error occurred. Please give us some time, we are looking into this!”
]
+“ErrorDetails”: “”
+“ProcessingTimeInMilliseconds”: “609”
}
@afx Thanks for posting the details, and for your email with the Form Assembly file link. I checked the request header of your PDF file in Chrome developer tools and it turns out that the MIME type is wrong. For a PDF file, it should be application/pdf.
On our side, the error message “internal error” is very confusing and not helpful at all. We will provide a better error message with the next update.
I don’t have any way of specifying the MIME type form From Assembly, and we are instead (and have been) passing the fileType PDF parameter. But that is not working now either.
We haven’t changed anything on our end since this stopped working. Thanks.
The issue has been fixed on the free API endpoint. You can now overwrite the automatic file type detection (which is based on the MIME type) with FILETYPE=....
Once everything is stable we will roll out the patch to all PRO OCR API endpoints in the next days, too. Meanwhile you can use the free endpoint with your PRO api key, too.
I see this still isn’t working on the paid servers. Any update on when it will be applied to them? thanks…
I never made the switch to the free version, as I paid for the paid version due to the needs I have regarding pdf images, sizes, etc. So, I would really, really, appreciate it if this is pushed up as soon as possible. Kinda crippling a specific aspect of our process that I rely on a service like this for.
Hi, you can use the free endpoint also with your PRO and PROPDF api key. Then you have the same features as the PRO endpoints (minus the redundancy and speed, of course).
We always roll out features on the free endpoint first. This way we make sure that only stable updates reach the PRO endpoints.
In this case we did not push it to the PRO endpoints yet as we were waiting for a few other improvements. But the update will happen either this weekend or early next week.