hello every one we are stucking in a problem we want to exteact formatted contents from pdf we are extracting contents but it is simple but our requirement for formatted contents like tables, paragraph, heading font family and style etc
kindly help us it is urgent we are losing clients
Did you enable the table ocr mode? This ensures that the result is returned table line by table line.
But note that our OCR API returns the text and its position (x/y word coordinates). It does not return information like font family and style.
sir kindly tell me how can i format my this pdf file to its exact text location
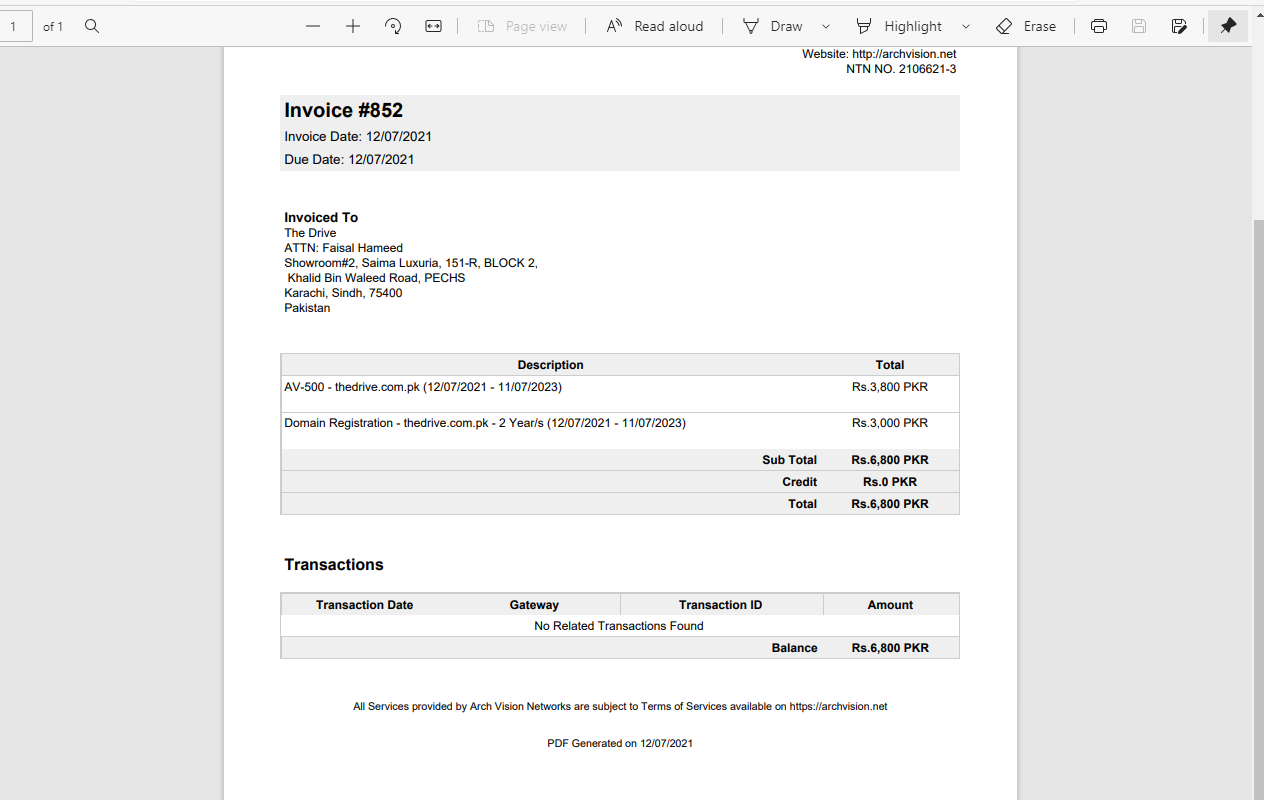
as it is giving result if it is converted by using your php code::
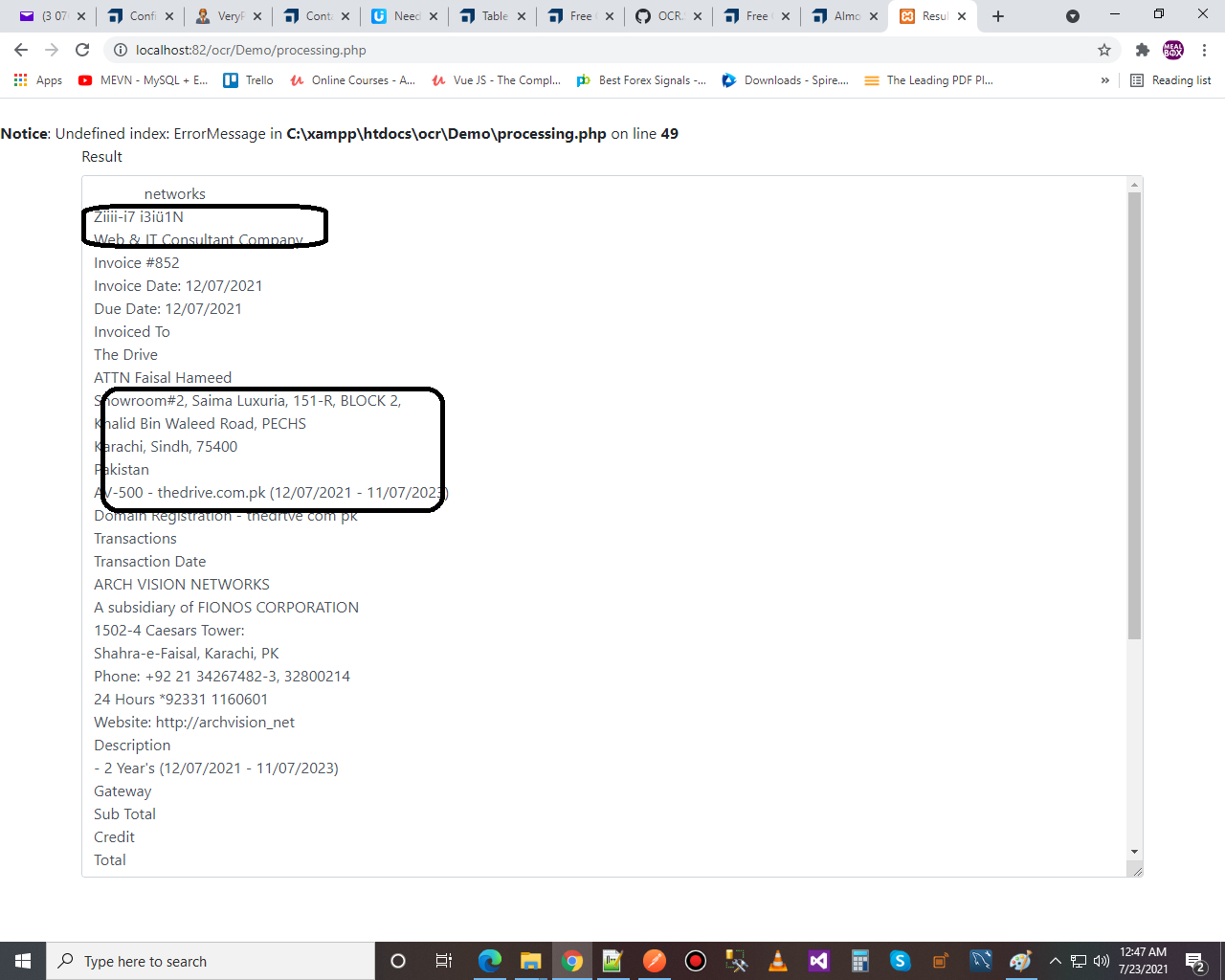
please rply me as soon as possible we are running out of time
I am not sure I understand the question. The returned data contains the x/y position of every word group, or?
Did you have a fix on this issue? I am facing the same issue last time but no response from anyone and couldn’t find the topic troubleshooting in google.