Hi guys – I’ve been using ocr.space for OCR’ing Traditional Chinese text and most recently started to use it for Japanese text as well. I have generally been really happy with the result and even wrote a Discord Bot so that I can use it more easily.
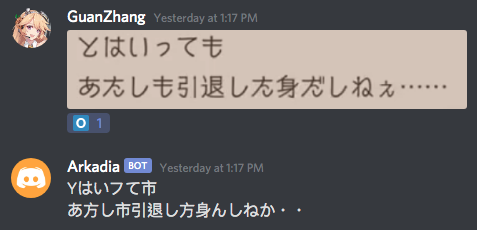
Currently I’m trying to OCR some text from a Japanese mobile game, and it’s been giving minor issues such as this. Are there any options we can tweak to make it more accurate? I’m guessing the font kinda throws the OCR engine off. Thanks a lot in advance!
The online version uses scale=true by default right? In that case I have tried both the online version and via the API and they both show the same issue. If you think the issue is with the resolution of the image I can potentially try a higher-resolution one. I wonder if it would be possible to train the engine with this new font because it always seem to make the same mistakes, thanks!
The API uses scale=false by default. But the online ocr has scaling turned ON by default (see the checkbox in the web form).
The OCR engine is pre-trained, so you (as a user) can not train it. But of course we continually improve it. => Do you have a few more images for us where the detection has problems?
Yeah so I tested both options already and they both have the same issue.
Here are some more images from the game, if you need more please let me know, thanks!
I’m actually trying to transcribe the text found in this video (from the game), so if you need more samples you can grab those there. Please let me know if you need anything else to improve detection of this font, thanks a lot!