In the python example you provided it is not shown how to incorporate the parameters ‘isCreateSearchablePdf’: true, ‘isSearchablePdfHideTextLayer’: false
As shown below I put them in the payload but this didnt work.I didnt get a link to a searchable PDF.How should this be accomplished? TIA
import requests
from dotenv import load_dotenv
import os
import json # Import the json module
import PyPDF2
def ocr_space_file(filename, overlay=False, api_key_default ='helloworld', language='eng'):
""" OCR.space API request with local file.
Python3.5 - not tested on 2.7
:param filename: Your file path & name.
:param overlay: Is OCR.space overlay required in your response.
Defaults to False.
:param api_key: OCR.space API key.
Defaults to 'helloworld'.
:param language: Language code to be used in OCR.
List of available language codes can be found on https://ocr.space/OCRAPI
Defaults to 'en'.
:return: Result in JSON format.
"""
payload = {'isOverlayRequired': overlay,
'apikey': api_key_default,
'language': language,
}
with open(filename, 'rb') as f:
r = requests.post('https://api.ocr.space/parse/image',
files={filename: f},
data=payload,
)
return r.content.decode()
def ocr_space_url(url, overlay=False, api_key_default ='helloworld', language='eng'):
""" OCR.space API request with remote file.
Python3.5 - not tested on 2.7
:param url: Image url.
:param overlay: Is OCR.space overlay required in your response.
Defaults to False.
:param api_key: OCR.space API key.
Defaults to 'helloworld'.
:param language: Language code to be used in OCR.
List of available language codes can be found on https://ocr.space/OCRAPI
Defaults to 'en'.
:return: Result in JSON format.
"""
payload = {'url': url,
'isOverlayRequired': overlay,
'isCreateSearchablePdf': true,
'isSearchablePdfHideTextLayer': false,
'apikey': api_key,
'language': language,
}
r = requests.post('https://api.ocr.space/parse/image',
data=payload,
)
return r.content.decode()
# Use examples:
load_dotenv('.env')
api_key = os.getenv('API_KEY')
filename: str = r'L:\Projects\NPL - GPT\NPL GPT Staging\Case 202402480 112228452_clean.pdf'
test_file = ocr_space_file(filename=filename, language='eng')
print(test_file)
# test_url = ocr_space_url(url='http://i.imgur.com/31d5L5y.jpg')
parsed_result = json.loads(test_file)
if "ParsedResults" in parsed_result:
# Initialize an empty string to store all text
all_text = ""
# Loop through each page
for page_num, page_result in enumerate(parsed_result["ParsedResults"]):
ocr_text = page_result.get("ParsedText", "")
print("Extracted text from page {}:".format(page_num + 1))
print(ocr_text)
# Append the text from this page to the overall text
all_text += ocr_text
# Save the extracted text to a text file
output_filename = "extracted_text.txt"
with open(output_filename, "w") as output_file:
output_file.write(all_text)
print("Saved extracted text from all pages to {}".format(output_filename))
else:
print("No OCR results found.")
Small issue first: The api key should be in header. It works in the body, too, but this is deprecated.
I am not sure why the searchable PDF generation fails. Looks all ok on first glance.
Have you tried to call the OCR API with Postman? Does it work there for you?
Thank you for your response. Below is my latest script. A mistake I made before is that I but the searchable pdf parameters inside the url code but not the file code. I corrected that. The issue I have is that I am not getting a link to a searchable PDF. Where would I find it? In the JSON or in the extracted text or both. I am not getting an error. The text is being extracted properly. Also, I’m not sure what you meant be telling me to reloate the api_ley. Please be explicit. Thank you ( I am not a python expert)
import requests
from dotenv import load_dotenv
import os
import json # Import the json module
import PyPDF2
def ocr_space_file(filename, overlay=False, api_key_default ='helloworld', language='eng'):
""" OCR.space API request with local file.
Python3.5 - not tested on 2.7
:param filename: Your file path & name.
:param overlay: Is OCR.space overlay required in your response.
Defaults to False.
:param api_key: OCR.space API key.
Defaults to 'helloworld'.
:param language: Language code to be used in OCR.
List of available language codes can be found on https://ocr.space/OCRAPI
Defaults to 'en'.
:return: Result in JSON format.
"""
payload = {'isOverlayRequired': False,
'isCreateSearchablePdf': True,
'isSearchablePdfHideTextLayer': False,
'apikey': api_key_default,
'language': language,
}
with open(filename, 'rb') as f:
r = requests.post('https://api.ocr.space/parse/image',
files={filename: f},
data=payload,
)
return r.content.decode()
def ocr_space_url(url, overlay=False, api_key_default ='helloworld', language='eng'):
""" OCR.space API request with remote file.
Python3.5 - not tested on 2.7
:param url: Image url.
:param overlay: Is OCR.space overlay required in your response.
Defaults to False.
:param api_key: OCR.space API key.
Defaults to 'helloworld'.
:param language: Language code to be used in OCR.
List of available language codes can be found on https://ocr.space/OCRAPI
Defaults to 'en'.
:return: Result in JSON format.
"""
"""
payload = {'url': url,
'isOverlayRequired': False,
'isCreateSearchablePdf': True,
'isSearchablePdfHideTextLayer': False,
'apikey': api_key,
'language': language,
}
"""
r = requests.post('https://api.ocr.space/parse/image',
data=payload,
)
return r.content.decode()
# Use examples:
load_dotenv('.env')
api_key = os.getenv('API_KEY')
filename: str = r'L:\Projects\NPL - GPT\NPL GPT Staging\Case 202402480 112228452_clean.pdf'
test_file = ocr_space_file(filename=filename, language='eng')
print(test_file)
# test_url = ocr_space_url(url='http://i.imgur.com/31d5L5y.jpg')
parsed_result = json.loads(test_file)
if "ParsedResults" in parsed_result:
# Initialize an empty string to store all text
all_text = ""
# Loop through each page
for page_num, page_result in enumerate(parsed_result["ParsedResults"]):
ocr_text = page_result.get("ParsedText", "")
print("Extracted text from page {}:".format(page_num + 1))
print(ocr_text)
# Append the text from this page to the overall text
all_text += ocr_text
# Save the extracted text to a text file
output_filename = "extracted_text.txt"
with open(output_filename, "w") as output_file:
output_file.write(all_text)
print("Saved extracted text from all pages to {}".format(output_filename))
else:
print("No OCR results found.")paste code here
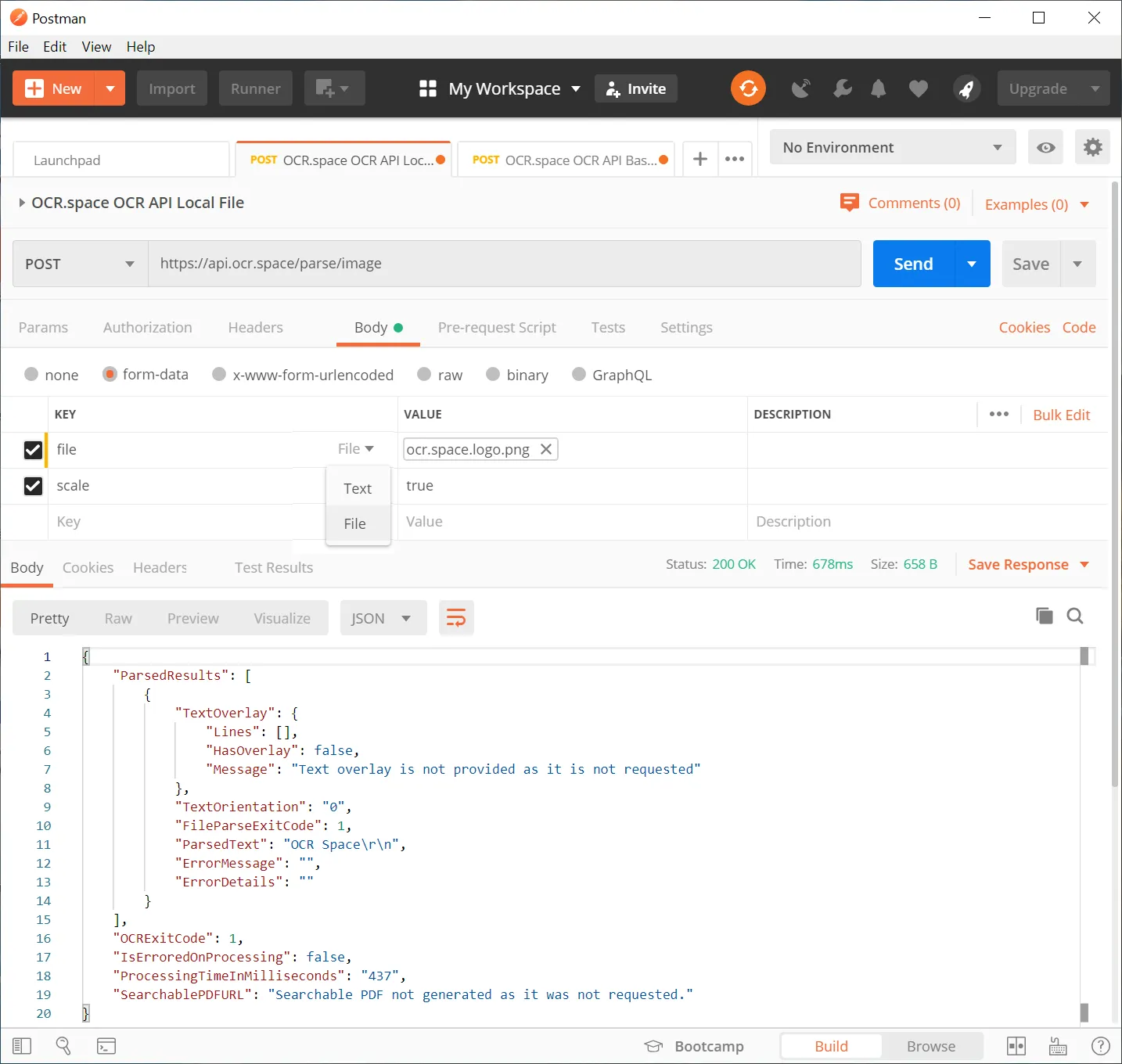
I highly recommend that you first test the API with Postman:
You probably know it, but just in case: Postman is a free app, see test ocr api.
If you see the problem even with Postman, a screenshot of the result is helpful.
Thanks for response. I am familiar with postman. I will try it None of your options have to do with using file as source. Only url. is this correct?
Here is an example with file upload. You also find it here: Free OCR API
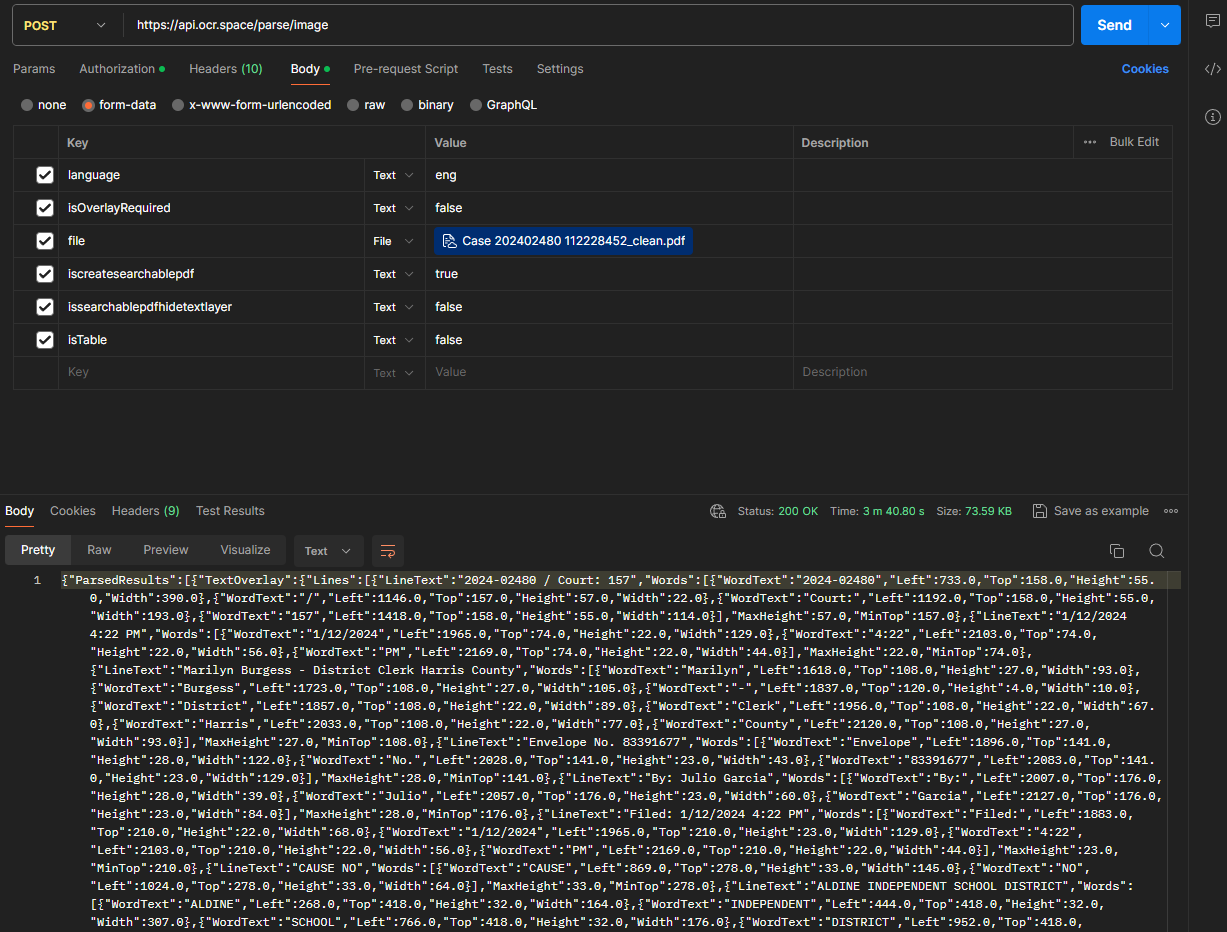
I ran in postman for the case of a pdf file. The extraction is good. I don’t see where I am getting a link to the searchable pdf. Where should I look for it?
BTW-what is overlay text?
I saw in your documentation that the searchable link is at the end of the JSON. I looked for it and it was there,- so problem solved
“Message”:“Total lines: 12”},“TextOrientation”:“0”,“FileParseExitCode”:1,“ParsedText”:“…“District\r\n”,“ErrorMessage”:”“,“ErrorDetails”:”"}],“OCRExitCode”:1,“IsErroredOnProcessing”:false,“ProcessingTimeInMilliseconds”:“5197”,“SearchablePDFURL”:“https://pdf-111.ocr.space/SearchablePDF/140a6503-576c-426d-bac0-e2776d6a84c6.pdf”}
{kind=link}