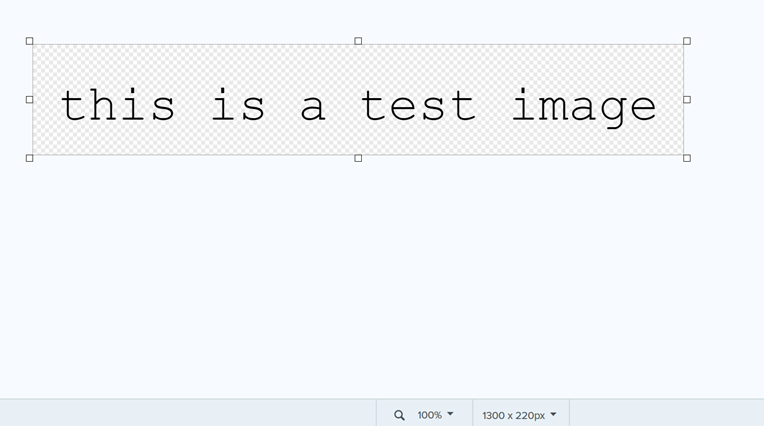
Hello. Not sure what I’m doing wrong. Here is my image

Here is the result after uploading the image at https://ocr.space/ and clicking Start OCR!
{
“ParsedResults”: [
{
“Overlay”: {
“Lines”: [],
“HasOverlay”: true,
“Message”: “Total lines: 0”
},
“FileParseExitCode”: 1,
“TextOrientation”: “0”,
“ParsedText”: “”,
“ErrorMessage”: “”,
“ErrorDetails”: “”
}
],
“OCRExitCode”: 1,
“IsErroredOnProcessing”: false,
“ProcessingTimeInMilliseconds”: 2.218,
“SearchablePDFURL”: “(not requested)”
}
I can see there that “ParsedText”: “”, so I assume no text was found. What features of my image make it difficult for your server to read? What do I need to change?