Hello,
I am having the hardest time finding a solution to this problem. I am trying to screen scrape the data from a webpage, then paste it into a Google doc.
I have tried OCRExtract (the output is very far off), storetext, storevalue, and have tried the screenshot feature.
Here is what the webpage looks like:
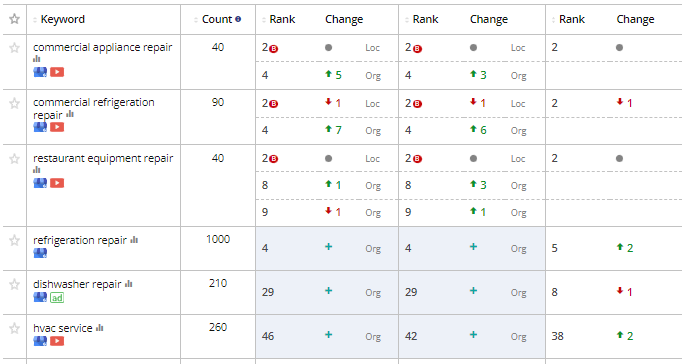
-
OCRrelative - the result that it outputs looks nothing like the data.
-
With storetext/storevalue - I get an error code ( [error][ignored]
Line 33: timeout reached when looking for element ‘xpath=//“contentWrapper”]/div[4]/div/div[2]/div[10]/div/table[2]/thead/tr[2]/th[2]/div’ -
With the screenshot. There is not a great way to get the screenshot to the clipboard.
Anyone have a solution to this or have experience with a similar problem?