
I am super happy with the OCR results which are great, my only problem is regarding the Overlay. I need to know the position of the text. Somehow I have everything returned but the bounding boxes are mirrored, sometimes vertical and horizontal. When looking into the Json File it tells me Text Orientation 0 even though I put in text upside down. Are you familiar with the issue ?
Hi, are you using OCR Engine1 or 2?
I am using engine 2!
The overlay is always returned upright, never rotated. But if the image has e. g. a 90° rotation, the JSON response contains the parameter "TextOrientation": "90", => You can use this rotate the overlay as required.
Having said this, currently engine2 has a bug and the “TextOrientation” is alwas returned as “0”. → We will fix this ASAP.
Ok that is good to know with the orientation. There is another thing with the bounding boxes that I have noticed.
def create_result_dictionary_ocr(self, url, image):
image_width, image_height = image.shape[1], image.shape[0]
data_dict = json.loads(url)
lines = data_dict["ParsedResults"][0]['TextOverlay']['Lines']
result_dict = {
idx: {
'text': word['WordText'],
'bounding_box': {
'Left': word['Left'],
'Top': word['Top'],
'Height': word['Height'],
'Width': word['Width']
}
}
for idx, line in enumerate(lines)
for word in line['Words']
}
# Feasibility check using list comprehensions
max_left = max(word['bounding_box']['Left'] for word in result_dict.values())
max_top = max(word['bounding_box']['Top'] for word in result_dict.values())
# swap dimensions
if max_left > image_width or max_top > image_height:
print("switch dimensions")
for word in result_dict.values():
word['bounding_box']['Left'], word['bounding_box']['Top'], word['bounding_box']['Width'], word['bounding_box']['Height'] = word['bounding_box']['Top'], word['bounding_box']['Left'], word['bounding_box']['Height'], word['bounding_box']['Width']
# Filtering out single-character special signs and re-indexing
filtered_signs = set(string.punctuation + "°§")
final_dict = {
i: value
for i, value in enumerate(word for word in result_dict.values() if not (len(word['text']) == 1 and word['text'] in filtered_signs))
}
return final_dict
When I return the boxes sometimes the dimensions do not add up with the dimensions of the image. Basically what happens is that they are returned 90° rotated. So let’s say my image is 2.000 x 400 Pixels it will tell me left in range [0:400] and top [0:2.000]. So what I do is I take the max top & left value of the bounding box to see if they match the dimensions. If one of the surpasses it I switch it
Did I understand that correctly? So you found a way to detect the orientation from the API response?
Well no not really. This is a picture with the “feasibility” check off:
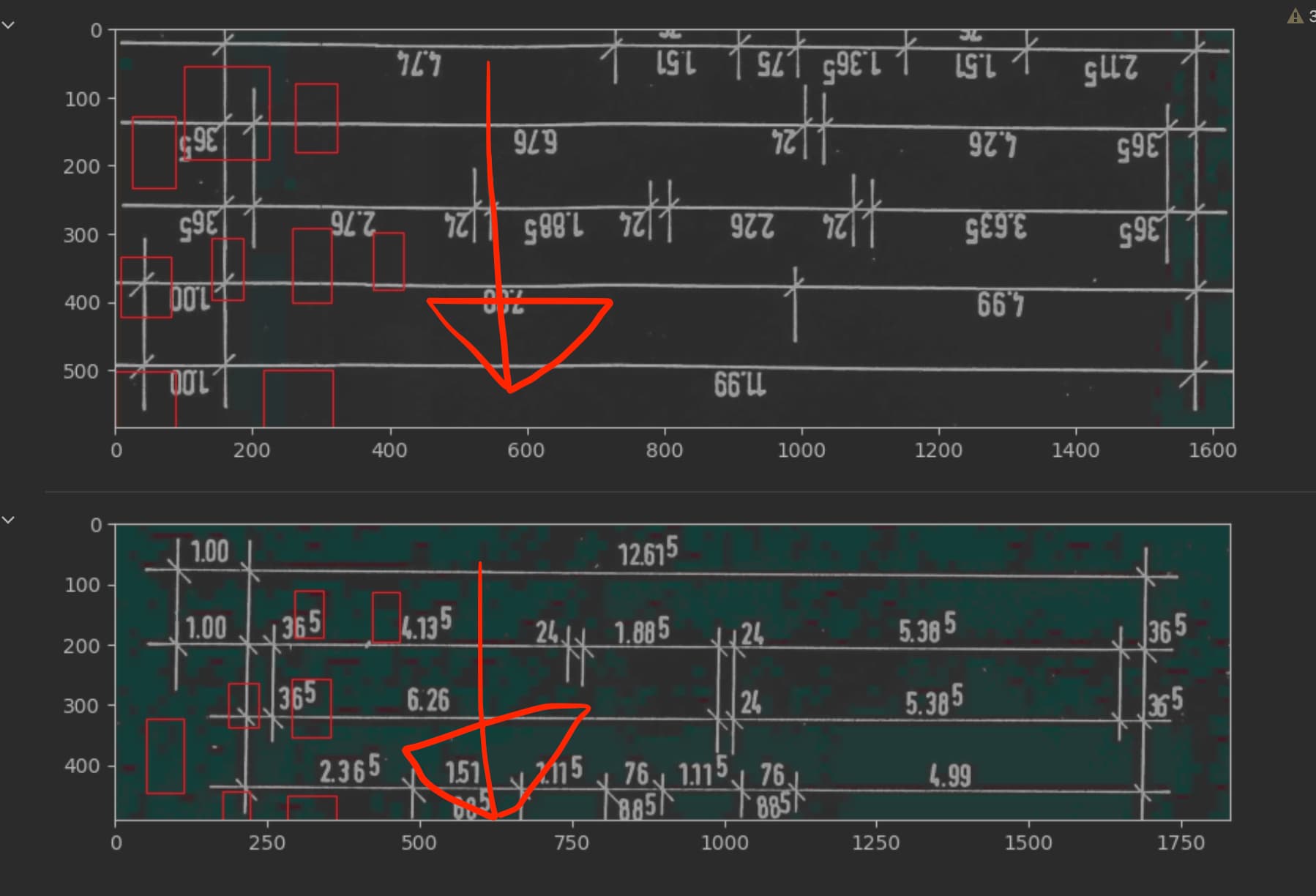
See the issue here is that the direction is entirely wrong the bounding boxes returned are not even matching the dimensions of the image. Top & left are swapped. Hence the orientation directs downwards.
In about 40% of the cases the feasibility check jumps in and swaps left and top so it matches the images dimension. I am simply ensuring that the dimensions match. If the dimensions match the bounding boxes are still rotated. That goes for both picture were the feasibility check kicks in and not!
Is there an answer for this Problem by now ? ![]()