Hey thanks for explaining that for me!
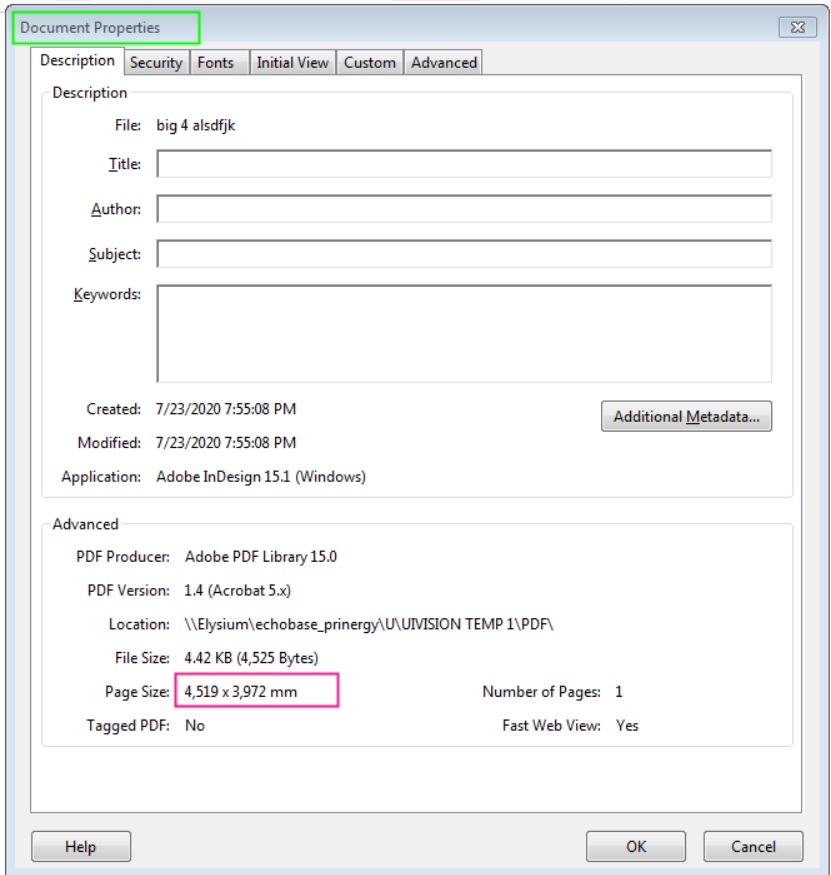
Yes I’m trying to just read width and height dimensions (only numbers) and then I parse them into two separate variables which I then use later in the workflow to set a page size in another application.
A friend of mine wrote two regex javascripts to parse the information, remove commas from 4 digit page sizes etc.
However I’m finding that sometimes the OCRExtract misses the decimal point - making the width 10 times larger. Or it struggles with 3’s and B’s.
Love to hear any additional tips on getting accuracy!