I have tried to parse PDF file using OCR API via Postman.But I didn’t get the output
as I expected.In the output JSON format some of the words are missing .
Kindly help me with this. 
Can you please attach the PDF? And also mention a few words (of the text) that are OCR’ed wrong?
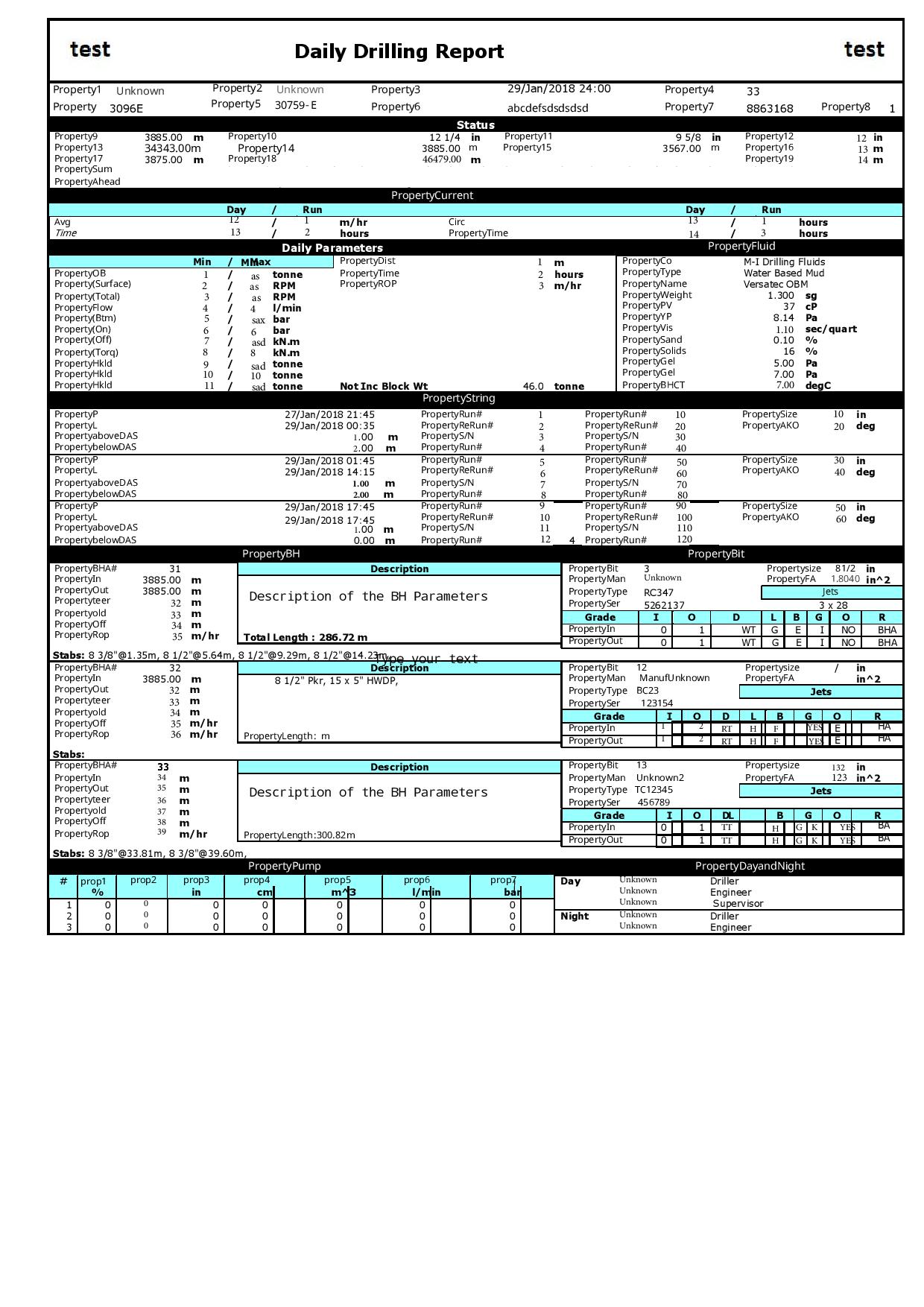
I have already shared my PDF File. Can someone please help me to parse this.