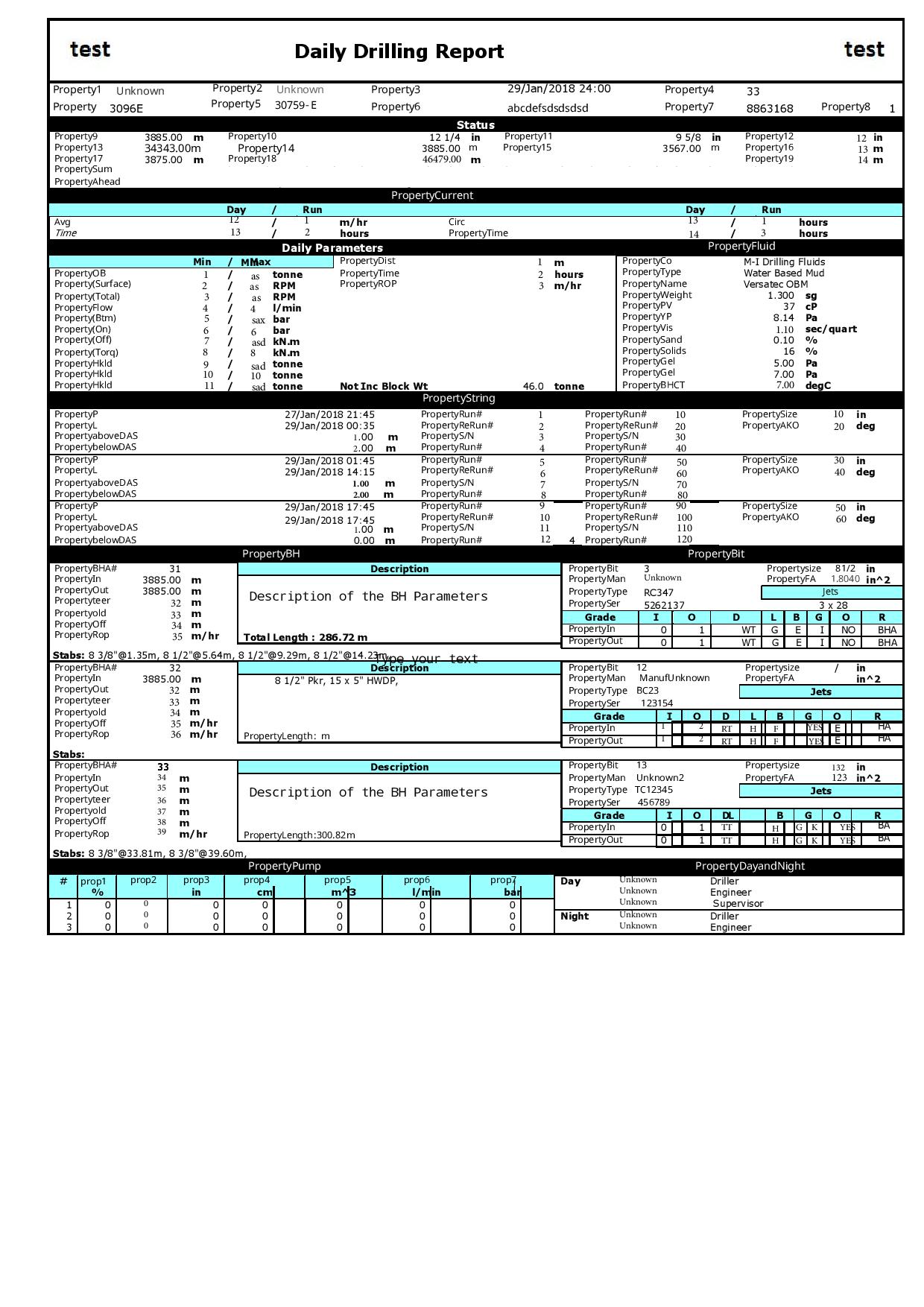
I have tried to parse PDF file using OCR API via Postman.But I didn’t get the output as I expected.In the output JSON format some of the words are missing .Kindly help me with this.
Here am attaching sample file also
I have tried to parse PDF file using OCR API via Postman.But I didn’t get the output as I expected.In the output JSON format some of the words are missing .Kindly help me with this.
Here am attaching sample file also